
SAMENVATTING
Reinforcement Learning voor Developers in 2026
Een praktische gids om slimme, autonome AI-agenten te bouwen met Reinforcement Learning en Python in 2026.
Keywords: Reinforcement Learning, AI Ontwikkeling, Python
INHOUDSOPGAVE
1 Achtergrond: De Opkomst van Reinforcement Learning
2 Kerninhoud: De Fundamenten van Reinforcement Learning
3 Algoritmes in Reinforcement Learning: Een Overzicht
4 Praktische Toepassing: Bouw Je Eerste Slimme Agent met Python
5 Geavanceerde Concepten en Toekomstperspectieven
6 Veelgestelde Vragen (FAQ)
ACHTERGROND
De Opkomst van Reinforcement Learning
In het snel evoluerende landschap van kunstmatige intelligentie (AI) is Reinforcement Learning (RL) uitgegroeid tot een van de meest fascinerende en potentieel revolutionaire takken. Waar traditionele Machine Learning methoden zoals Supervised en Unsupervised Learning zich richten op patroonherkenning in bestaande data, staat RL centraal in het aanleren van optimale besluitvorming in complexe, dynamische omgevingen. Denk aan autonome voertuigen die hun weg vinden in het verkeer, robots die ingewikkelde taken uitvoeren, of AI die menselijke kampioenen verslaat in complexe spellen zoals Go en schaken. Deze indrukwekkende prestaties zijn allemaal voortgekomen uit de principes van Reinforcement Learning.
Voor developers die verder willen kijken dan de standaardtoepassingen van AI, biedt RL een krachtig paradigma om systemen te bouwen die echt ‘slim’ zijn – systemen die leren door te experimenteren, fouten te maken en te optimaliseren op basis van feedback. Het is de kern van adaptief gedrag en autonome intelligentie. In 2026 zien we een versnelde adoptie van RL in diverse industrieën, gedreven door verbeterde algoritmes, krachtigere hardware en de groeiende beschikbaarheid van specialistische frameworks. Dit maakt het een essentieel domein voor elke developer die relevant wil blijven in de AI-revolutie.
“Reinforcement Learning stelt ons in staat om systemen te creëren die niet alleen data verwerken, maar ook actief de wereld om hen heen beïnvloeden en daarvan leren, wat leidt tot echte autonome intelligentie.”
— Kwonnis Analyse, 2026
De conceptuele eenvoud van Reinforcement Learning, waarbij een agent leert via ’trial-and-error’ in een omgeving, maskeert een diepgaande wiskundige en computationele complexiteit. Toch is de kernidee universeel: een agent voert acties uit, ontvangt een beloning (of straf) en een nieuwe staat van de omgeving, en gebruikt deze feedback om zijn toekomstige gedrag te verbeteren. Dit iteratieve proces, vaak over miljoenen simulaties, stelt de agent in staat om strategieën te ontdekken die voor mensen onintuïtief zouden zijn. Dit is precies wat RL zo krachtig maakt voor problemen waar traditionele programmeerlogica tekortschiet.
KERNPUNT
Reinforcement Learning overbrugt de kloof tussen data-analyse en autonome besluitvorming, waardoor het de sleutel is tot de volgende generatie AI-toepassingen in 2026 en daarna.
Dit artikel duikt dieper in de wereld van Reinforcement Learning, beginnend bij de fundamentele concepten en evoluerend naar praktische implementaties met Python. We zullen de bouwstenen van een RL-systeem ontleden, de meest invloedrijke algoritmes verkennen en ten slotte een stap-voor-stap handleiding bieden om je eigen slimme agent te bouwen. Het doel is om je als developer de kennis en vaardigheden te geven om de potentie van RL te ontsluiten en bij te dragen aan de ontwikkeling van geavanceerde AI-oplossingen.
KERNINHOUD
De Fundamenten van Reinforcement Learning
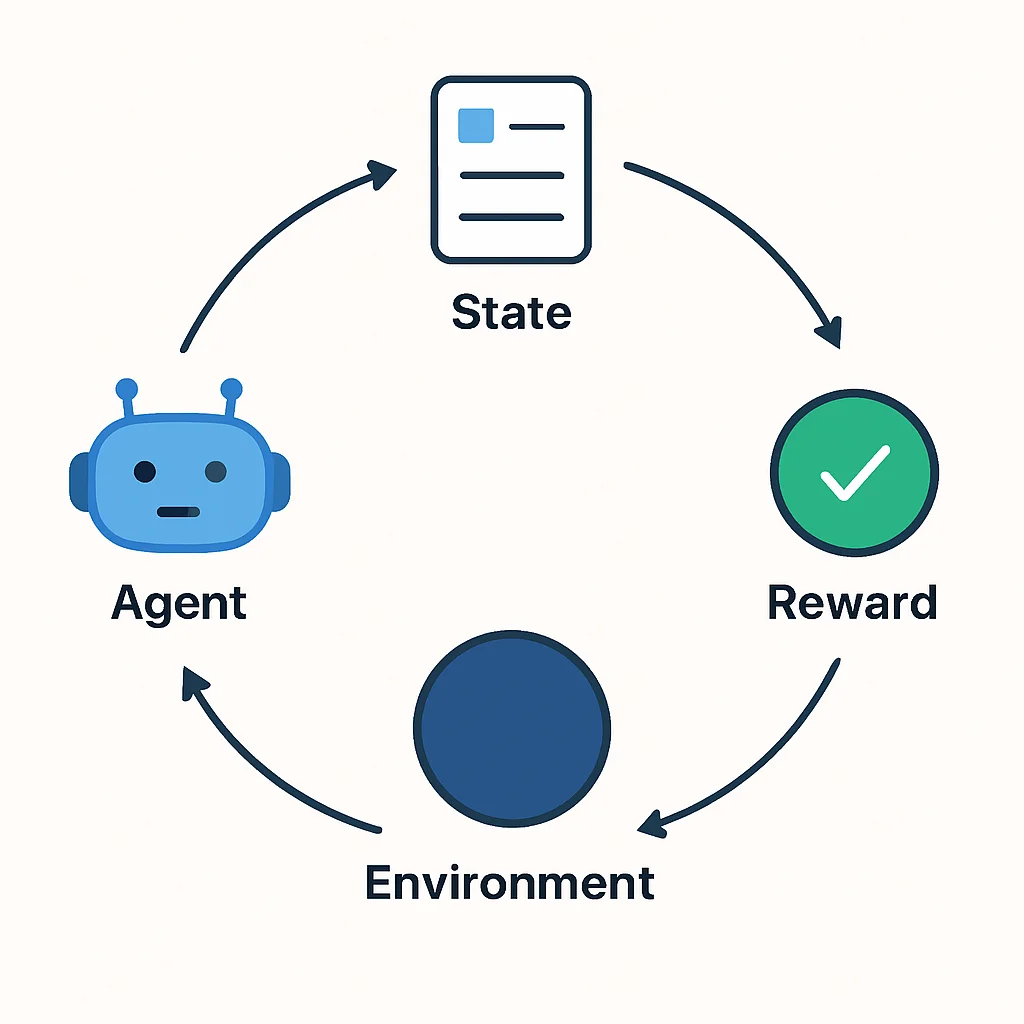
Om Reinforcement Learning te begrijpen, is het cruciaal om de kerncomponenten en hun interacties te doorgronden. Deze elementen vormen de basis van elk RL-systeem en bepalen hoe een agent leert en beslissingen neemt.
Agent, Omgeving, Actie, Staat, Beloning
De interactie tussen deze vijf elementen definieert de Reinforcement Learning-cyclus:
- Agent: Dit is de lerende of beslissende entiteit. De agent observeert de omgeving, neemt beslissingen en voert acties uit. Het doel van de agent is om zijn cumulatieve beloning over tijd te maximaliseren.
- Omgeving: Alles buiten de agent. De omgeving reageert op de acties van de agent door een nieuwe staat te presenteren en een beloning (of straf) terug te geven. Voorbeelden zijn een schaakbord, een virtuele robotwereld of een economisch model.
- Staat (State, S): Een complete beschrijving van de situatie van de omgeving op een bepaald moment. Dit kan variëren van de posities van stukken op een bord tot sensordata van een robot. De agent gebruikt de staat om zijn volgende actie te bepalen.
- Actie (Action, A): Een beweging of beslissing die de agent kan uitvoeren binnen de omgeving. De set van mogelijke acties is afhankelijk van de omgeving.
- Beloning (Reward, R): Een numerieke waarde die de agent ontvangt van de omgeving na het uitvoeren van een actie in een bepaalde staat. Positieve beloningen moedigen gewenst gedrag aan, negatieve beloningen (straffen) ontmoedigen ongewenst gedrag. Het is de primaire feedback die de agent gebruikt om te leren.
De RL-Loop
1. Observatie — Agent observeert de huidige staat (S) van de omgeving.
2. Actie — Agent kiest en voert een actie (A) uit op basis van zijn beleid.
3. Feedback — Omgeving geeft een beloning (R) en een nieuwe staat (S’) terug.
4. Leren — Agent update zijn beleid of waardefunctie om toekomstige beslissingen te verbeteren.
Beleid (Policy)
Het beleid, vaak aangeduid als π, is de strategie van de agent. Het definieert hoe de agent zich gedraagt, oftewel hoe het een actie kiest gegeven een bepaalde staat. Een beleid kan deterministisch zijn (altijd dezelfde actie voor een staat) of stochastisch (een kansverdeling over acties). Het uiteindelijke doel van Reinforcement Learning is om een optimaal beleid te vinden dat de verwachte cumulatieve beloning maximaliseert.
Waardefuncties (Value Functions)
Waardefuncties kwantificeren hoe goed een agent zich in een bepaalde staat bevindt, of hoe goed een specifieke actie is in die staat. Ze zijn essentieel voor het evalueren van beleid en het sturen van leerprocessen:
- Staat-waardefunctie (V-waarde):
V(s)geeft de verwachte toekomstige cumulatieve beloning aan die een agent kan verwachten als hij start in staatsen daarna een bepaald beleidπvolgt. - Actie-waardefunctie (Q-waarde):
Q(s, a)geeft de verwachte toekomstige cumulatieve beloning aan als de agent actieauitvoert in staats, en daarna beleidπvolgt. De Q-waarde is vaak directer bruikbaar voor het kiezen van acties, omdat het de waarde van elke actie in een gegeven staat evalueert.
De Bellman-vergelijking
De Bellman-vergelijking is een fundamentele recursieve relatie die de waardefuncties met elkaar verbindt. Het stelt dat de waarde van een staat (of een staat-actiepaar) gelijk is aan de directe beloning plus de verdisconteerde waarde van de volgende staat (of staat-actiepaar). De disconteringsfactor (γ, gamma) bepaalt het belang van toekomstige beloningen; een hogere gamma (0 <= γ <= 1) betekent dat toekomstige beloningen zwaarder wegen.
CODE-UITLEG
De Bellman-vergelijking voor de optimale actie-waardefunctie (Q*) is cruciaal. Het stelt dat de optimale Q-waarde voor een staat-actiepaar gelijk is aan de directe beloning plus de maximaal mogelijke verdisconteerde Q-waarde van de volgende staat.
Q*(s, a) = R(s, a) + γ * max_a' Q*(s', a')Deze vergelijking is de basis voor veel RL-algoritmes, waaronder Q-Learning, die we later zullen behandelen.
Exploratie vs. Exploitatie
Een van de grootste uitdagingen in Reinforcement Learning is het afwegen van exploratie (het verkennen van nieuwe acties en staten om meer te leren over de omgeving) en exploitatie (het benutten van de reeds bekende optimale acties om de beloning te maximaliseren). Te veel exploratie kan leiden tot inefficiënt leren en lage beloningen, terwijl te veel exploitatie de agent kan laten vastlopen in suboptimale strategieën omdat het nooit betere paden ontdekt. Dit dilemma is fundamenteel voor het ontwerp van effectieve RL-algoritmes.
KERNPUNT
Het vinden van de juiste balans tussen exploratie en exploitatie is cruciaal voor de effectiviteit van een Reinforcement Learning agent. Dit wordt vaak beheerd met technieken zoals de epsilon-greedy strategie, waarbij de agent met een kleine kans willekeurige acties kiest.

ALGORITMES
Algoritmes in Reinforcement Learning: Een Overzicht
De wereld van Reinforcement Learning wordt bevolkt door een reeks algoritmes, elk met zijn eigen benadering om het optimale beleid te vinden. Deze algoritmes kunnen grofweg worden ingedeeld op basis van hoe ze omgaan met de omgeving en hoe ze hun beleid leren.
Model-Based vs. Model-Free RL
Een belangrijke dichotomie in RL is of een algoritme een model van de omgeving gebruikt:
- Model-Based RL: Deze algoritmes proberen eerst een model van de omgeving te leren, d.w.z., ze proberen te voorspellen wat de volgende staat zal zijn en welke beloning ze zullen ontvangen voor elke actie. Met dit model kunnen ze vervolgens plannen en simulaties uitvoeren om het optimale beleid te vinden zonder daadwerkelijk interactie met de echte omgeving. Dit kan efficiënter zijn in termen van benodigde interacties met de omgeving, maar het leren van een nauwkeurig model kan complex zijn.
- Model-Free RL: Deze algoritmes leren direct van interacties met de omgeving, zonder expliciet een model te bouwen. Ze leren door trial-and-error, wat betekent dat ze veel ervaring nodig hebben, maar ze zijn robuuster wanneer de omgeving onbekend of te complex is om te modelleren. De meeste praktische toepassingen van RL, vooral met Deep Learning, vallen in deze categorie.
“De keuze tussen model-gebaseerde en model-vrije methoden hangt sterk af van de complexiteit van de omgeving en de beschikbaarheid van interacties, waarbij model-vrije methoden vaak de voorkeur genieten in realistische, complexe scenario’s.”
— Kwonnis Analyse, 2026
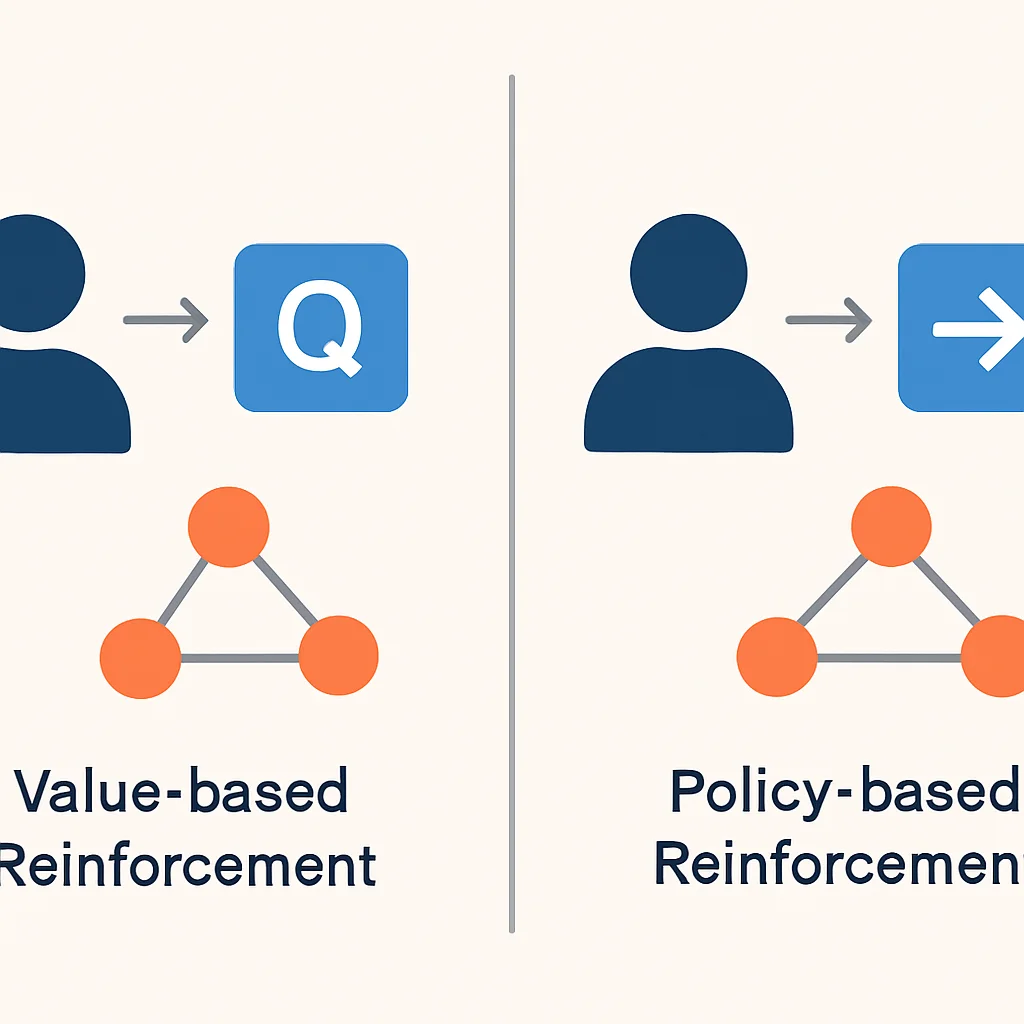
Value-Based Methoden: Q-Learning en SARSA
Value-based methoden richten zich op het leren van een waardefunctie (meestal de Q-functie) die de verwachte toekomstige beloningen voor elke actie in elke staat schat. Zodra de optimale Q-functie is geleerd, kan de agent eenvoudig de actie kiezen met de hoogste Q-waarde voor de huidige staat.
- Q-Learning: Dit is een van de meest populaire en eenvoudig te begrijpen model-vrije algoritmes. Het is een off-policy algoritme, wat betekent dat het de optimale Q-waarden leert, ongeacht het beleid dat de agent volgt om te exploreren. De update-regel is gebaseerd op de Bellman-vergelijking.
- SARSA (State-Action-Reward-State-Action): Dit is een on-policy algoritme, wat betekent dat het de Q-waarden leert voor het beleid dat de agent op dat moment volgt. Het gebruikt de volgende actie die daadwerkelijk wordt genomen om de Q-waarde te updaten, in tegenstelling tot Q-Learning dat de maximale Q-waarde van de volgende staat gebruikt. SARSA is doorgaans veiliger in risicovolle omgevingen omdat het rekening houdt met het beleid van exploratie.
CODE-UITLEG
De Q-Learning update-regel is de kern van het algoritme. Het past de Q-waarde van een staat-actiepaar aan op basis van de ontvangen beloning en de maximaal verwachte toekomstige beloning van de volgende staat. α (alfa) is de leerfrequentie, γ (gamma) is de disconteringsfactor.
Q(s, a) = Q(s, a) + α * [R + γ * max_a' Q(s', a') - Q(s, a)]Policy-Based Methoden: REINFORCE en Actor-Critic
Policy-based methoden leren direct een beleid, zonder expliciet een waardefunctie te leren. Ze optimaliseren de parameters van het beleid om de verwachte beloning te maximaliseren. Dit is vaak effectiever in omgevingen met continue acties of zeer grote toestandsruimtes.
- REINFORCE: Een eenvoudig algoritme dat de beleidsparameters update op basis van de totale beloning van een complete episode. Het is een Monte Carlo-methode, wat betekent dat het pas leert aan het einde van een episode.
- Actor-Critic: Deze methoden combineren elementen van zowel value-based als policy-based methoden. Ze hebben twee componenten: een ‘Actor’ die het beleid leert (welke actie te nemen) en een ‘Critic’ die een waardefunctie leert om de acties van de Actor te evalueren. Dit leidt vaak tot stabieler en efficiënter leren.
KERNPUNT
De keuze van het algoritme hangt af van de aard van de omgeving (discrete vs. continue staten/acties), de complexiteit en de efficiëntie-eisen. Q-Learning is een uitstekend startpunt voor discrete omgevingen.
Deep Reinforcement Learning (DRL)
De doorbraak van Deep Learning heeft Reinforcement Learning getransformeerd. Deep Reinforcement Learning (DRL) integreert diepe neurale netwerken in RL-algoritmes om waardefuncties of beleid te approximeren. Dit is cruciaal voor het omgaan met omgevingen met extreem grote of continue toestands- en actieruimtes, zoals videobeelden of robotbesturing.
- DQN (Deep Q-Networks): Een van de eerste en meest invloedrijke DRL-algoritmes, dat Q-Learning combineert met diepe neurale netwerken. DQN heeft menselijke prestaties overtroffen in Atari-spellen door direct te leren van pixelinput.
- A2C (Advantage Actor-Critic) en PPO (Proximal Policy Optimization): Dit zijn populaire Actor-Critic methoden die Deep Learning gebruiken om zowel de Actor als de Critic te implementeren. Ze staan bekend om hun stabiliteit en prestaties in complexe omgevingen.
DRL heeft de grenzen van wat mogelijk is met AI verlegd en blijft een actief onderzoeksgebied met continue innovaties in 2026.
PRAKTISCHE TOEPASSING
Bouw Je Eerste Slimme Agent met Python
Nu we de theoretische fundamenten hebben behandeld, is het tijd om de handen uit de mouwen te steken en je eigen Reinforcement Learning agent te bouwen. We gebruiken Python, de de facto taal voor AI en Machine Learning, en de OpenAI Gym-bibliotheek, een toolkit voor het ontwikkelen en vergelijken van RL-algoritmes.
De Omgeving: OpenAI Gym
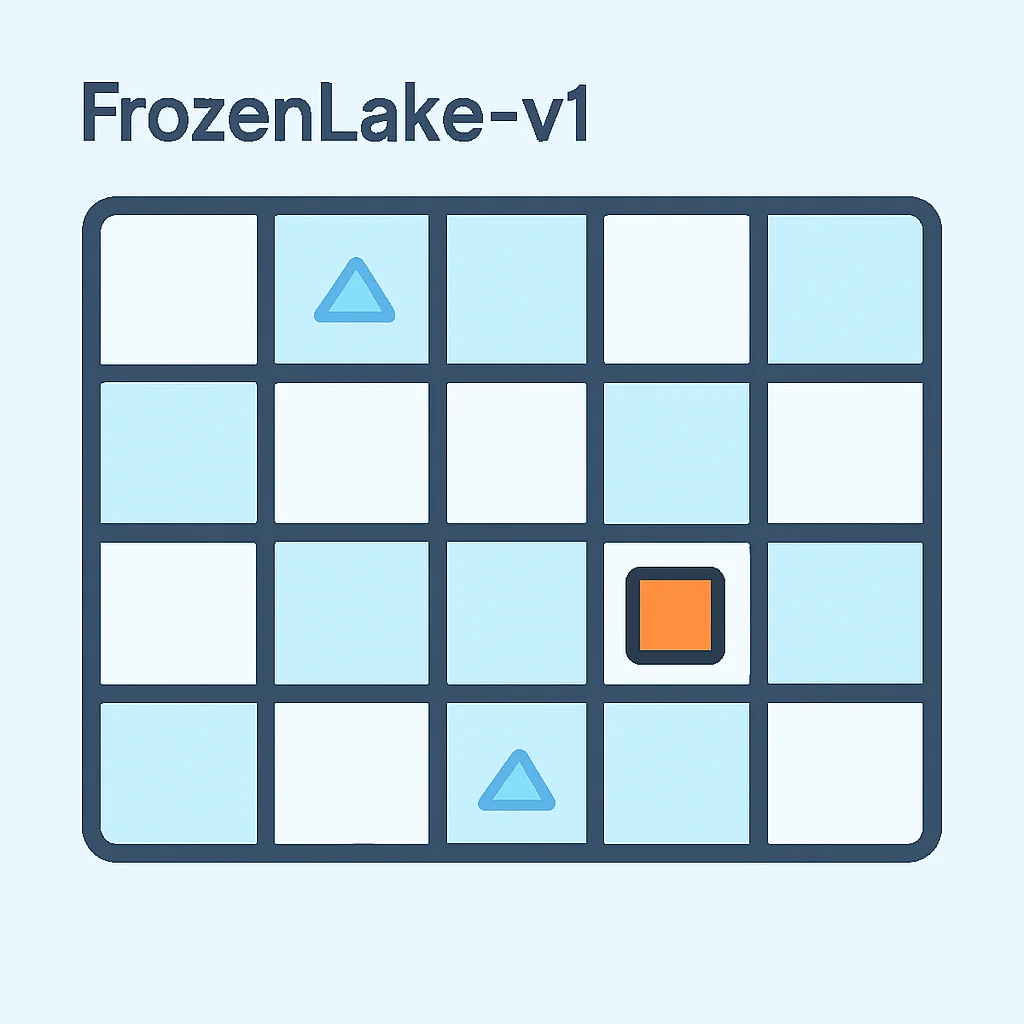
OpenAI Gym biedt een gestandaardiseerde interface voor verschillende RL-omgevingen. Voor deze tutorial gebruiken we de "FrozenLake-v1" omgeving. In dit spel moet een agent over een bevroren meer navigeren van een startpunt naar een doelwit, terwijl hij gaten vermijdt. Het is een discrete omgeving met een beperkt aantal staten (de tegels op het meer) en acties (omhoog, omlaag, links, rechts).
Setup: Python en Bibliotheken
Zorg ervoor dat je Python 3.8+ hebt geïnstalleerd. Installeer vervolgens de benodigde bibliotheken:
CODE-UITLEG
Deze commando’s installeren de gym en numpy bibliotheken. gym biedt de RL-omgevingen en numpy is essentieel voor numerieke operaties, zoals het beheren van onze Q-tabel.
pip install gym==0.26.0 numpy1
Omgeving Initialiseren
Creëer een instantie van de FrozenLake-omgeving en inspecteer de eigenschappen.
CODE-UITLEG
We importeren gym en maken een omgeving aan. observation_space.n geeft het aantal mogelijke staten (tegels) en action_space.n het aantal mogelijke acties (richtingen).
import gym
import numpy as np
# Initialiseer de omgeving
env = gym.make("FrozenLake-v1", is_slippery=False) # is_slippery=False voor een deterministische omgeving
env.reset()
print(f"Aantal staten: {env.observation_space.n}")
print(f"Aantal acties: {env.action_space.n}")
Voor FrozenLake (4×4) zal dit 16 staten en 4 acties retourneren.
2
Q-Tabel Initialiseren
We gebruiken een Q-tabel om de Q-waarden op te slaan. Dit is een NumPy-array met dimensies (aantal staten) x (aantal acties).
CODE-UITLEG
De Q-tabel wordt geïnitialiseerd met nullen. Dit betekent dat we in het begin geen voorkeur hebben voor enige actie in enige staat.
# Initialiseer de Q-tabel met nullen
q_table = np.zeros((env.observation_space.n, env.action_space.n))
print(f"Q-tabel vorm: {q_table.shape}")
3
Het Q-Learning Algoritme Implementeren
Nu implementeren we de Q-Learning update-regel en de epsilon-greedy strategie voor exploratie.
CODE-UITLEG
Deze sectie definieert de hyperparameters voor Q-Learning, zoals de leerfrequentie (learning_rate), de disconteringsfactor (discount_factor) en de parameters voor de epsilon-greedy strategie (epsilon, max_epsilon, min_epsilon, decay_rate). Het aantal episodes (num_episodes) bepaalt hoe lang de agent traint.
# Hyperparameters
learning_rate = 0.9 # Alfa
discount_factor = 0.9 # Gamma
epsilon = 1.0 # Startwaarde van epsilon voor exploratie
max_epsilon = 1.0 # Maximale exploratiekans
min_epsilon = 0.01 # Minimale exploratiekans
decay_rate = 0.001 # Hoe snel epsilon afneemt
num_episodes = 20000 # Aantal trainingsepisodes
KERNPUNT
De epsilon waarde neemt geleidelijk af tijdens de training, waardoor de agent in het begin meer exploreert en later meer exploiteert, wat essentieel is voor effectief leren.
PROBLEEM 01
Suboptimale prestaties door onbalans in exploratie/exploitatie.
Als een agent te weinig exploreert, kan hij vastlopen in een lokale optimum en nooit de optimale strategie ontdekken. Te veel exploratie vertraagt het leren en resulteert in inefficiënt gedrag.
OPLOSSING — Epsilon-greedy strategie met decay.
De epsilon-greedy strategie zorgt ervoor dat de agent met een kans epsilon een willekeurige actie kiest (exploratie) en met een kans 1-epsilon de actie met de hoogste Q-waarde kiest (exploitatie). Door epsilon geleidelijk te laten afnemen, verschuift de focus van exploratie naar exploitatie naarmate de agent meer leert.
4
De Agent Trainen en Evalueren
We implementeren nu de training-loop die de agent door duizenden episodes leidt.
CODE-UITLEG
Deze code traint de agent over het gespecificeerde aantal episodes. Voor elke episode reset de omgeving en simuleert de agent stappen totdat de episode eindigt (doel bereikt of gat). De Q-tabel wordt bijgewerkt bij elke stap. De epsilon waarde neemt af na elke episode.
# Lijst om beloningen per episode op te slaan
rewards_per_episode = []
# Training loop
for episode in range(num_episodes):
state, info = env.reset() # Reset de omgeving voor een nieuwe episode
done = False # Vlag om aan te geven of de episode is afgelopen
rewards_current_episode = 0
for step in range(100): # Maximaal 100 stappen per episode
# Epsilon-greedy strategie voor actie selectie
if np.random.uniform(0, 1) < epsilon:
action = env.action_space.sample() # Exploreer: kies een willekeurige actie
else:
action = np.argmax(q_table[state,:]) # Exploit: kies de beste actie uit de Q-tabel
# Voer de gekozen actie uit en observeer de volgende staat en beloning
new_state, reward, done, truncated, info = env.step(action)
# Update de Q-tabel met de Bellman-vergelijking
q_table[state, action] = q_table[state, action] + learning_rate * (
reward + discount_factor * np.max(q_table[new_state, :]) - q_table[state, action]
)
state = new_state
rewards_current_episode += reward
if done or truncated:
break
# Epsilon decay
epsilon = min_epsilon + (max_epsilon - min_epsilon) * np.exp(-decay_rate*episode)
rewards_per_episode.append(rewards_current_episode)
env.close() # Sluit de omgeving na training
# Evalueer de prestaties
sum_rewards = np.sum(rewards_per_episode)
print(f"Totale beloning over {num_episodes} episodes: {sum_rewards}")
print(f"Gemiddelde beloning per 100 episodes: {np.mean(rewards_per_episode[-100:])}")
print("\nGetrainde Q-tabel:")
print(q_table)
Na het uitvoeren van deze code zal je agent de FrozenLake-omgeving hebben geleerd. De Q-tabel zal waarden bevatten die de optimale strategie voor de agent vertegenwoordigen. Een hoge gemiddelde beloning over de laatste episodes duidt op succesvol leren.
9.2
/ 10
Q-Learning is een uitstekend algoritme voor discrete, overzichtelijke RL-problemen.
TOEKOMSTPERSPECTIEF
Geavanceerde Concepten en Toekomstperspectieven
De Q-Learning implementatie die we zojuist hebben voltooid, is een fantastische start, maar de wereld van Reinforcement Learning strekt zich veel verder uit. Voor complexere problemen, zoals die met continue toestands- of actieruimtes, of wanneer de omgeving te groot is om in een Q-tabel te passen, zijn geavanceerdere technieken nodig.
Deep Q-Networks (DQN)
Zoals eerder genoemd, combineert DQN Q-Learning met diepe neurale netwerken. In plaats van een Q-tabel te gebruiken, leert een neuraal netwerk de Q-waarden van staten en acties. Dit stelt de agent in staat om te generaliseren over staten die het nog nooit eerder heeft gezien, wat cruciaal is voor problemen met grote toestandsruimtes, zoals het spelen van Atari-spellen direct van pixelinput. Belangrijke innovaties binnen DQN zijn ‘experience replay’ (het opslaan en hergebruiken van ervaringen) en ’target networks’ (het stabiliseren van het leerproces).
Actor-Critic Methoden
Voor problemen met continue actieruimtes, waar het kiezen van de ‘beste’ actie uit een oneindig aantal mogelijkheden lastig is, zijn Actor-Critic methoden vaak superieur. Hierbij leert de “Actor” een beleid (een functie die direct acties genereert) en de “Critic” leert een waardefunctie om de kwaliteit van die acties te evalueren. Dit maakt efficiënter leren mogelijk in complexe robotica- en besturingsproblemen.
“De convergentie van Deep Learning en Reinforcement Learning heeft de deur geopend naar AI-systemen die in 2026 ongekende niveaus van autonomie en intelligentie bereiken.”
— Kwonnis Visie, 2026
Toepassingen in 2026
De impact van Reinforcement Learning is in 2026 al breed voelbaar en zal de komende jaren alleen maar toenemen:
- Autonome Systemen: Van zelfrijdende auto’s die leren navigeren in complex verkeer tot drones die complexe inspectietaken uitvoeren en industriële robots die zich aanpassen aan veranderende productielijnen.
- Gaming: Niet alleen voor het verslaan van menselijke spelers, maar ook voor het creëren van realistischer NPC-gedrag en het genereren van procedurele content.
- Financiële Handel: Agenten die leren optimale handelsstrategieën te ontwikkelen door te reageren op marktbewegingen en risico’s te beheren.
- Gepersonaliseerde Aanbevelingen: Systemen die leren welke aanbevelingen het meest effectief zijn voor individuele gebruikers door interactie en feedback te analyseren.
- Gezondheidszorg: Het optimaliseren van behandelplannen voor patiënten, het personaliseren van medicatiedoseringen en het beheren van ziekenhuisbronnen.
KERNPUNT
De toekomst van AI in 2026 is onlosmakelijk verbonden met de verdere ontwikkeling en toepassing van Reinforcement Learning, waarbij het vermogen om te leren van interactie de sleutel is tot adaptieve en intelligente systemen.
Voor developers biedt de snelle vooruitgang in DRL-frameworks zoals TensorFlow Agents en PyTorch-RL een rijk ecosysteem om te experimenteren en geavanceerde agenten te bouwen. Het is een spannend veld met enorme mogelijkheden voor innovatie en impact.
Veelgestelde Vragen (FAQ)
Q. Wat is het belangrijkste verschil tussen Reinforcement Learning en andere vormen van Machine Learning?
A. Reinforcement Learning (RL) richt zich op het aanleren van optimale besluitvorming door middel van trial-and-error in een dynamische omgeving, waarbij een agent beloningen ontvangt voor gewenst gedrag. Supervised Learning leert van gelabelde data, en Unsupervised Learning zoekt patronen in ongelabelde data, zonder expliciete feedback op acties.
Q. Welke programmeertalen en bibliotheken zijn het meest geschikt voor Reinforcement Learning in 2026?
A. Python is de dominante taal voor RL vanwege zijn uitgebreide ecosysteem. Belangrijke bibliotheken zijn OpenAI Gym voor omgevingen, NumPy voor numerieke berekeningen, en Deep Learning frameworks zoals TensorFlow (met TensorFlow Agents) en PyTorch (met PyTorch-RL, Stable Baselines3) voor Deep Reinforcement Learning.
Q. Wat zijn de grootste uitdagingen bij het toepassen van Reinforcement Learning in de praktijk?
A. Grote uitdagingen omvatten het ontwerpen van effectieve beloningsfuncties, de hoge computationele kosten en de benodigde hoeveelheid data (interacties) voor training, het omgaan met sparse rewards (zeldzame beloningen), en het garanderen van de veiligheid en interpreteerbaarheid van geleerde beleidsregels in complexe, real-world scenario’s.
Q. Kan Reinforcement Learning worden gebruikt voor problemen met continue acties, zoals het besturen van een robotarm?
A. Ja, absoluut. Hoewel Q-Learning beter geschikt is voor discrete acties, zijn algoritmes zoals Actor-Critic methoden (bijv. DDPG, TD3, SAC, PPO) speciaal ontworpen om continue actieruimtes aan te pakken. Deze algoritmes leren vaak een beleid dat direct een numerieke waarde voor elke actie genereert, in plaats van een selectie uit een vaste set.
Bedankt voor het lezen!
We hopen dat deze gids je een solide basis heeft gegeven om te beginnen met Reinforcement Learning en je eigen slimme agenten te bouwen. De mogelijkheden zijn eindeloos!
Vragen of opmerkingen? Deel ze hieronder!