
SAMENVATTING
Verbeter Je Backend Prestaties met Caching: Gids voor Redis en Strategieën in 2026
Ontdek hoe je caching implementeert met Redis en andere strategieën om de prestaties van je backend applicaties te optimaliseren en schaalbaarheid te garanderen.
Keywords: backend, caching, Redis
INHOUDSOPGAVE
1. Achtergrond en Inleiding: De Noodzaak van Caching in 2026
2. Fundamenten van Caching en de Rol van Redis
3. Geavanceerde Caching Strategieën en Implementatie met Redis
4. Praktische Uitdagingen en Oplossingen bij Redis Caching
5. Implementatiegids: Redis Caching voor Backend API’s
6. Veelgestelde Vragen (FAQ)
1. Achtergrond en Inleiding: De Noodzaak van Caching in 2026
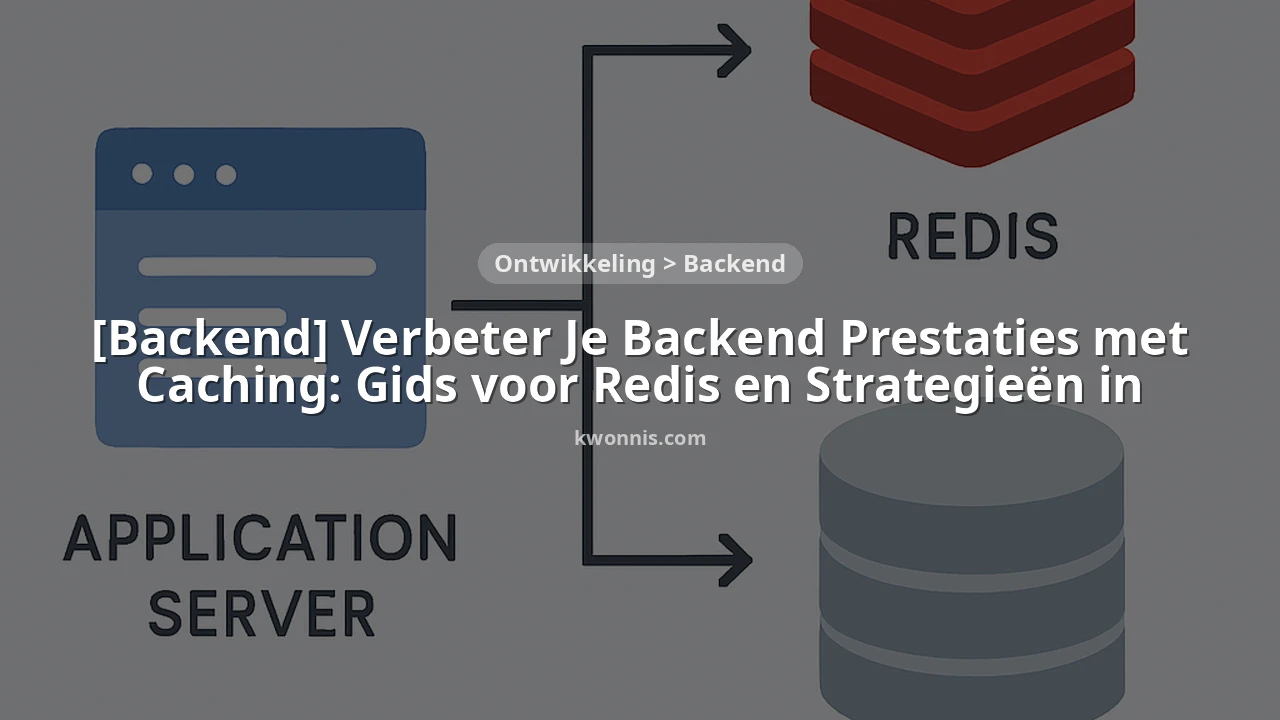
In het dynamische landschap van webontwikkeling anno 2026 is de vraag naar razendsnelle en schaalbare applicaties hoger dan ooit. Gebruikers verwachten onmiddellijke respons, en elke milliseconde vertraging kan leiden tot verlies van engagement en omzet. Denk aan e-commerceplatforms waar 1 seconde extra laadtijd kan resulteren in een daling van 7% in conversies, of streamingdiensten waar buffering direct leidt tot frustratie bij de gebruiker. De backend, het hart van elke applicatie, staat onder constante druk om enorme hoeveelheden data te verwerken en te leveren aan duizenden, zo niet miljoenen gelijktijdige gebruikers.
Traditionele backend-architecturen, die sterk afhankelijk zijn van directe databasequery’s voor elke aanvraag, lopen snel tegen hun grenzen aan. Databases zijn geoptimaliseerd voor persistentie en transactie-integriteit, maar niet voor pure snelheid bij het leveren van identieke, veelgevraagde data. Dit is waar caching in beeld komt: een cruciale techniek om de prestaties te verbeteren door veelgevraagde gegevens tijdelijk op te slaan op een sneller toegankelijke locatie.
De voordelen van caching zijn veelzijdig. Het vermindert de belasting op databases, waardoor deze zich kunnen concentreren op schrijfbewerkingen en complexe query’s. Dit leidt tot een lagere latency voor de eindgebruiker, een hogere doorvoer (meer aanvragen per seconde) en een verbeterde schaalbaarheid van de gehele applicatie. Bovendien kan caching de operationele kosten verlagen door minder database-resources te verbruiken en de noodzaak voor dure database-upgrades uit te stellen.
KERNPUNT
Caching is in 2026 geen optie meer, maar een absolute noodzaak voor elke schaalbare backend-applicatie die voldoet aan de hoge verwachtingen van gebruikers en de efficiëntie van resources optimaliseert.
In deze gids duiken we diep in de wereld van caching, met een specifieke focus op Redis. We zullen de fundamentele concepten van caching verkennen, de mechanismen van Redis als een in-memory datastructuurserver analyseren, en geavanceerde strategieën bespreken die u kunt implementeren om de prestaties van uw backend aanzienlijk te verbeteren. Of u nu een doorgewinterde backend-ontwikkelaar bent of net begint met het optimaliseren van applicaties, deze gids biedt de inzichten en praktische voorbeelden om uw caching-strategieën naar een hoger niveau te tillen.
2. Fundamenten van Caching en de Rol van Redis
Voordat we de diepte ingaan met Redis, is het essentieel om een solide begrip te hebben van wat caching precies inhoudt en welke typen er bestaan. Caching is het proces van het opslaan van kopieën van bestanden of gegevens in een tijdelijke opslaglocatie, genaamd een cache, zodat toekomstige verzoeken voor die gegevens sneller kunnen worden verwerkt. Het is vergelijkbaar met het hebben van een kladblok naast uw bureau voor veelgebruikte aantekeningen, in plaats van telkens naar de archiefkast te lopen.
2.1 Typen Caching
Caching kan op verschillende niveaus van een applicatie-architectuur worden toegepast, elk met zijn eigen voordelen en gebruiksscenario’s:
Diverse Caching Niveaus
Browser Caching — De webbrowser slaat statische assets (afbeeldingen, CSS, JS) op om herhaalde downloads te voorkomen. Gecontroleerd via HTTP-headers zoals Cache-Control.
CDN Caching (Content Delivery Network) — Netwerk van servers die geografisch verspreid zijn om content dichter bij de gebruiker te brengen, waardoor latency wordt verminderd en de belasting van de oorspronkelijke server wordt vermenigvuldigd. Ideaal voor globale schaalbaarheid.
Applicatie Caching — De focus van dit artikel. Caching binnen de backend-applicatie of op een aparte cacheserver. Slaat databasequeryresultaten, gecomputeerde objecten of API-responsen op.
Database Caching — Veel databasesystemen hebben een interne cache voor queryresultaten of veelgevraagde blokken. Echter, dit is vaak beperkt en niet altijd efficiënt voor complexe applicatie-specifieke caching.
OS Caching — Het besturingssysteem cachet veelgebruikte bestandsblokken in het geheugen. Dit is een laag niveau en buiten directe controle van de applicatie-ontwikkelaar.
2.2 Introductie tot Redis: De Krachtpatser voor Caching
Redis (Remote Dictionary Server) is een open-source, in-memory datastructuurserver die vaak wordt gebruikt als database, cache en message broker. Het onderscheidt zich door zijn ongeëvenaarde snelheid, flexibiliteit en brede ondersteuning voor diverse datastructuren. Met Redis kunnen gegevens direct vanuit het RAM-geheugen worden gelezen en geschreven, wat resulteert in responstijden die vaak in de microseconden liggen.
Waarom Redis zo populair is in 2026:
✓ Uitzonderlijke Snelheid: Als in-memory systeem biedt Redis extreem lage latency en hoge doorvoer, essentieel voor real-time applicaties. Benchmarktests tonen vaak tienduizenden tot honderdduizenden operaties per seconde.
✓ Veelzijdige Datastructuren: In tegenstelling tot eenvoudige key-value stores biedt Redis ondersteuning voor Strings, Hashes, Lists, Sets, Sorted Sets, Streams en Geospatial indexes. Dit opent de deur naar complexe caching-strategieën.
✓ Persistentie Opties: Hoewel het primair een in-memory database is, biedt Redis opties voor persistentie (RDB snapshots en AOF logging) om gegevensverlies bij herstart te voorkomen.
✓ Atomiciteit: Alle Redis-bewerkingen zijn atomair, wat betekent dat ze volledig worden uitgevoerd of helemaal niet, wat de gegevensintegriteit waarborgt.
✓ Schaalbaarheid: Redis ondersteunt clustering, replicatie en sharding, waardoor het horizontaal schaalbaar is voor grote, gedistribueerde systemen.
✓ Actieve Community en Ecosystem: Een grote en actieve community, met uitgebreide documentatie en clientbibliotheken voor vrijwel elke programmeertaal.
2.3 Redis versus Memcached: Een Korte Vergelijking
Memcached is een andere populaire in-memory key-value cache. Hoewel het uitstekend presteert voor eenvoudige caching van strings, heeft Redis een aantal belangrijke voordelen die het in 2026 vaak de voorkeur geven voor complexere backend-systemen:
Redis Voordelen t.o.v. Memcached
✓ Complexere Datastructuren: Redis ondersteunt Lists, Hashes, Sets, Sorted Sets, wat Memcached niet doet. Dit maakt Redis geschikt voor meer dan alleen eenvoudige objectcaching.
✓ Persistentie: Redis biedt opties om gegevens op schijf op te slaan, wat Memcached niet heeft. Dit betekent dat bij een herstart de cache niet volledig leeg is.
✓ Replicatie en Clustering: Redis heeft ingebouwde mechanismen voor replicatie (master-replica) en clustering voor hoge beschikbaarheid en horizontale schaalbaarheid, wat Memcached mist.
✓ Pub/Sub Functionaliteit: Redis kan fungeren als een message broker met Publish/Subscribe-functionaliteit, wat nuttig is voor real-time updates en cache-invalidatie.
✓ Transacties: Redis ondersteunt atomiciteit van meerdere commando’s via transacties, wat de consistentie van data verbetert.
Voor de meeste moderne backend-applicaties die meer nodig hebben dan een simpele key-value store, biedt Redis een robuustere en flexibelere oplossing. Memcached blijft een valide optie voor zeer grootschalige, eenvoudige caching behoeften waar absolute minimalisme en snelheid prioriteit hebben en persistentie onbelangrijk is.
3. Geavanceerde Caching Strategieën en Implementatie met Redis
Het implementeren van caching is meer dan alleen het opslaan van gegevens. Het vereist een doordachte strategie om de voordelen te maximaliseren en valkuilen te vermijden. Hier bespreken we de meest voorkomende caching strategieën en hoe Redis deze ondersteunt met zijn veelzijdige datastructuren.
3.1 Gangbare Caching Strategieën
De keuze van een caching strategie hangt af van factoren zoals de lees-/schrijfverhouding van uw data, de tolerantie voor stale data en de complexiteit van de applicatie.
Belangrijkste Caching Strategieën
Cache-Aside (Lazy Loading) — De applicatie is verantwoordelijk voor het lezen uit de cache en, als de data niet aanwezig is (cache miss), het ophalen uit de database en deze vervolgens in de cache te plaatsen. Dit is de meest gangbare strategie.
Read-Through — De cache is de primaire databron. Als de data niet in de cache staat, haalt de cache zelf de data uit de database en retourneert deze. De applicatie hoeft niet direct met de database te communiceren.
Write-Through — Wanneer data wordt geschreven, wordt deze zowel naar de cache als naar de database geschreven. Dit zorgt voor consistentie, maar kan de schrijfsnelheid beïnvloeden.
Write-Back (Write-Behind) — Data wordt eerst naar de cache geschreven en pas later, asynchroon, naar de database. Dit biedt zeer snelle schrijfbewerkingen, maar brengt risico’s met zich mee bij cache-uitval.
Refresh-Ahead — De cache ververst proactief data voordat deze verloopt, gebaseerd op voorspellingen van toekomstige toegangspatronen. Vermindert cache misses en latency.
De Cache-Aside strategie is het meest flexibel en wordt het vaakst toegepast, omdat het de applicatie maximale controle geeft over wanneer en hoe data wordt gecachet. We zullen ons in de implementatievoorbeelden voornamelijk richten op deze strategie.
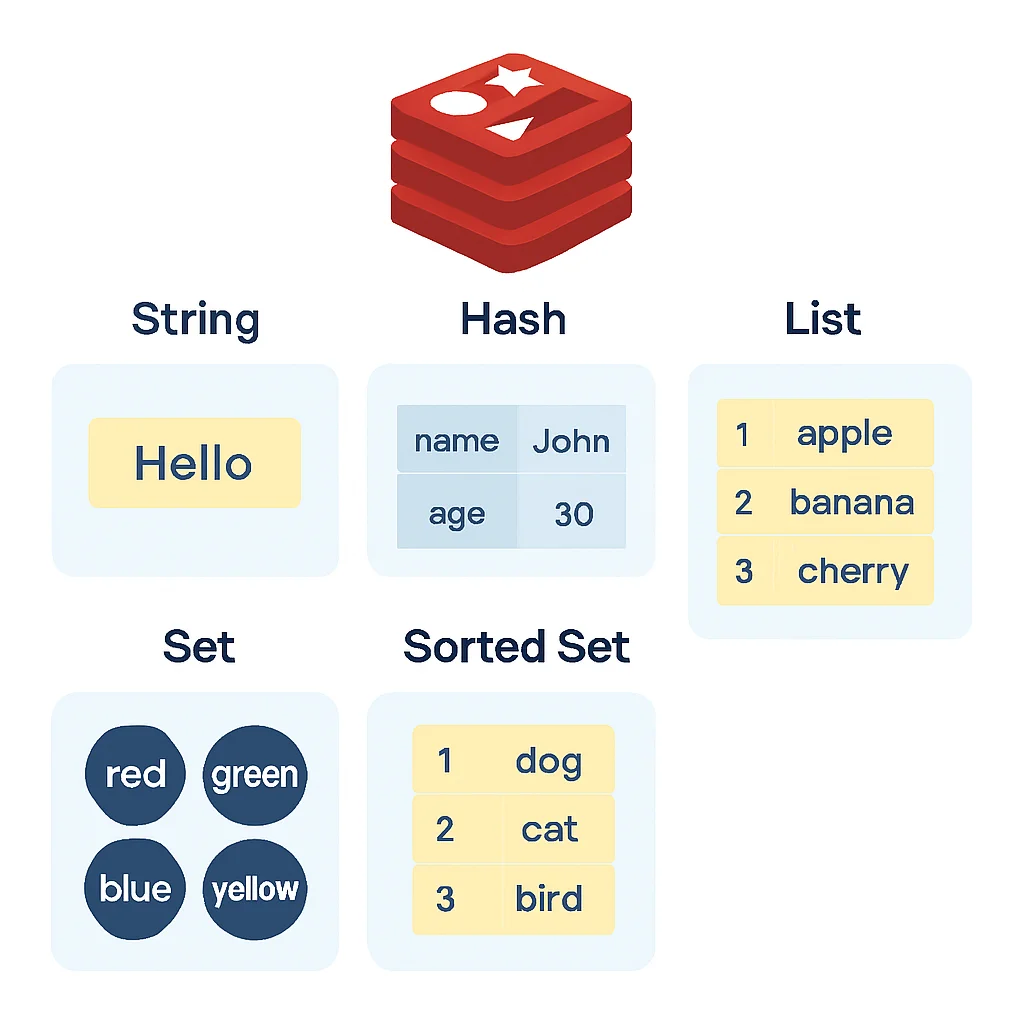
3.2 Redis Datastructuren voor Caching
Redis’ kracht ligt in zijn diverse datastructuren, die verder gaan dan een simpele string-opslag. Dit stelt ontwikkelaars in staat om complexe caching-scenario’s efficiënt te implementeren.
Strings: De meest eenvoudige datastructuur, ideaal voor het cachen van complete API-responsen, HTML-fragmenten of individuele objecten die geserialiseerd zijn naar JSON of XML. U kunt een Time-To-Live (TTL) instellen om de cache automatisch te laten verlopen.
CODE-UITLEG
Dit Python-voorbeeld toont hoe je een JSON-string opslaat in Redis met een TTL van 3600 seconden (1 uur) en deze vervolgens ophaalt.
import redis
import json
# Maak verbinding met Redis
r = redis.Redis(host='localhost', port=6379, db=0)
# Data om te cachen
user_data = {
"id": 123,
"name": "Alice Smith",
"email": "[email protected]",
"last_login": "2026-04-26T10:30:00Z"
}
user_id = "user:123"
# Cache de data als een JSON-string met een TTL van 1 uur (3600 seconden)
r.setex(user_id, 3600, json.dumps(user_data))
print(f"Data voor {user_id} gecachet met TTL van 3600 seconden.")
# Haal de data op uit de cache
cached_data_raw = r.get(user_id)
if cached_data_raw:
cached_data = json.loads(cached_data_raw)
print(f"Gecachete data voor {user_id}: {cached_data}")
else:
print(f"Data voor {user_id} niet gevonden in cache.")
# Probeer een niet-bestaande sleutel op te halen
non_existent_key = "user:999"
non_existent_data = r.get(non_existent_key)
print(f"Data voor {non_existent_key}: {non_existent_data}")
Hashes: Ideaal voor het opslaan van objecten met veel velden, zoals gebruikersprofielen of productinformatie. In plaats van het hele object als één string te serialiseren, kunt u elk veld van het object opslaan als een veld in een Redis Hash. Dit maakt het mogelijk om individuele velden van het object bij te werken zonder het hele object opnieuw te hoeven serialiseren en cachen.
CODE-UITLEG
Dit Python-voorbeeld demonstreert het gebruik van Redis Hashes om individuele velden van een gebruikersprofiel op te slaan en bij te werken. De TTL wordt op de hash-sleutel ingesteld.
import redis
r = redis.Redis(host='localhost', port=6379, db=0)
product_id = "product:456"
# Cache productdetails als een Hash
r.hset(product_id, mapping={
"name": "Super Widget",
"price": "99.99",
"stock": "150",
"category": "Electronics"
})
r.expire(product_id, 7200) # TTL van 2 uur
print(f"Product {product_id} gecachet als Hash.")
# Haal alle velden van het product op
product_details = r.hgetall(product_id)
decoded_product = {k.decode('utf-8'): v.decode('utf-8') for k, v in product_details.items()}
print(f"Gecachete productdetails: {decoded_product}")
# Update een specifiek veld (bijv. stock)
r.hset(product_id, "stock", "149")
print(f"Voorraad van {product_id} bijgewerkt.")
# Haal de bijgewerkte voorraad op
updated_stock = r.hget(product_id, "stock")
print(f"Nieuwe voorraad: {updated_stock.decode('utf-8')}")
Lists: Geschikt voor het cachen van chronologische data, zoals de meest recente blogposts, commentaren of een activiteitenfeed. Redis Lists gedragen zich als gekoppelde lijsten en ondersteunen snelle push- en pop-operaties aan beide uiteinden.
Sets: Voor het cachen van unieke items zonder specifieke volgorde, zoals een lijst met unieke gebruikers-ID’s die een bepaald artikel hebben bekeken, of tags die aan een item zijn gekoppeld. Sets ondersteunen snelle operaties voor het toevoegen, verwijderen en controleren op lidmaatschap.
Sorted Sets: Vergelijkbaar met Sets, maar elk lid heeft een score, waardoor de elementen gesorteerd kunnen worden op score. Dit is perfect voor leaderboards, trending topics of items met een ranking (bijv. de top 10 meest bekeken producten).
KERNPUNT
De keuze van de juiste Redis-datastructuur is cruciaal voor efficiënte caching. Strings zijn voor eenvoudige objecten, Hashes voor complexe objecten met velden, en Lists/Sets/Sorted Sets voor collecties en gerangschikte data.
4. Praktische Uitdagingen en Oplossingen bij Redis Caching
Hoewel caching enorme voordelen biedt, brengt het ook specifieke uitdagingen met zich mee. Een goed begrip hiervan en de bijbehorende oplossingen is essentieel voor een robuuste caching-strategie.
4.1 Cache Invalidatie en Consistentie
Het grootste probleem bij caching is “stale data” (verouderde gegevens). Hoe zorgt u ervoor dat de cache up-to-date blijft wanneer de onderliggende data in de database verandert?
PROBLEEM 01
Stale Data: Gecachete gegevens komen niet overeen met de database.
Een gebruiker update zijn profiel, maar de applicatie blijft de oude, gecachete gegevens tonen.
OPLOSSING
Time-To-Live (TTL): Stel een vervaltijd in voor elke cache-item. Na deze periode wordt het item automatisch uit de cache verwijderd en bij de volgende aanvraag opnieuw opgehaald uit de database. Dit is de eenvoudigste en meest voorkomende methode.
Write-Through / Write-Back: Zorg ervoor dat bij elke schrijfbewerking naar de database, de cache ook wordt bijgewerkt of geïnvalideerd. Bij Cache-Aside betekent dit dat u na een update de corresponderende cache-sleutel handmatig verwijdert (cache invalidatie).
Pub/Sub voor Invalidatie: Gebruik Redis’ Publish/Subscribe-mechanisme. Wanneer een database-update plaatsvindt, publiceert de applicatie een bericht naar een specifiek kanaal. Andere instanties van de applicatie (of andere services) die op dit kanaal abonneren, kunnen dan de relevante cache-items invalideren.
4.2 Cache Stampede en Thundering Herd
Wanneer een populair item in de cache verloopt of wordt geïnvalideerd, en plotseling duizenden gelijktijdige aanvragen voor dat item binnenkomen, kan dit leiden tot een “cache stampede” of “thundering herd”. Alle aanvragen missen de cache en belasten tegelijkertijd de onderliggende database, wat kan leiden tot downtime.
PROBLEEM 02
Overbelasting van de database door gelijktijdige cache misses.
Een nieuwsartikel wordt viraal. Zodra de cache verloopt, proberen miljoenen gebruikers tegelijkertijd het artikel op te halen uit de database.
OPLOSSING
Locking Mechanisme: Gebruik een gedistribueerd lock (bijv. met Redis’ SETNX of Redlock algoritme) om ervoor te zorgen dat slechts één applicatie-instantie de data uit de database haalt en in de cache plaatst. De andere aanvragen wachten op de lock of de cache-populatie.
Probabilistic Caching (Jitter): Voeg een kleine, willekeurige variatie toe aan de TTL van cache-items. Hierdoor verlopen cache-items niet allemaal tegelijk, wat de piekbelasting verspreidt.
Refresh-Ahead: Zoals eerder genoemd, proactief de cache verversen voordat deze verloopt, vermindert het aantal cache misses aanzienlijk.
4.3 Cold Start Probleem
Wanneer een cache leeg is (bijv. na een herstart van de Redis-server of de implementatie van een nieuwe applicatie), zullen de eerste aanvragen allemaal resulteren in cache misses en direct naar de database gaan. Dit kan leiden tot trage initiële prestaties.
PROBLEEM 03
Trage applicatiestart door een lege cache.
Na een deployment of serveronderhoud is de cache leeg, wat leidt tot een tijdelijke piek in databaseverkeer en slechte gebruikerservaring.
OPLOSSING
Cache Pre-populatie: Laad de cache proactief met de meest essentiële en veelgevraagde data tijdens het opstarten van de applicatie of na een herstart van de cache-server. Dit kan via batch-scripts of specifieke services.
Persistentie in Redis: Gebruik Redis’ RDB-snapshots of AOF-logging om de cache-status op schijf op te slaan. Bij een herstart kan Redis deze gegevens herstellen, waardoor de cache niet volledig leeg is.
“Warm-up” Traffic: Stuur gecontroleerd synthetisch verkeer naar de applicatie na een herstart om de cache geleidelijk te vullen voordat echte gebruikersverkeer binnenkomt.
4.4 Geheugenbeheer in Redis
Als in-memory database is het cruciaal om het geheugenverbruik van Redis te monitoren en te beheren om te voorkomen dat de server overbelast raakt of crasht.
KERNPUNT
Configureer maxmemory en een geschikte maxmemory-policy in uw Redis-configuratie (redis.conf) om onnodige geheugenproblemen te voorkomen.
Redis biedt verschillende maxmemory-policy opties om te bepalen welke items worden verwijderd wanneer het geheugenlimiet is bereikt:
noeviction: Nieuwe writes worden geweigerd wanneer het geheugen vol is.allkeys-lru: Verwijdert de minst recent gebruikte (Least Recently Used) sleutels uit alle sleutels.volatile-lru: Verwijdert de minst recent gebruikte sleutels, maar alleen die met een TTL ingesteld.allkeys-lfu: Verwijdert de minst frequent gebruikte (Least Frequently Used) sleutels uit alle sleutels. (Vanaf Redis 4.0)volatile-lfu: Verwijdert de minst frequent gebruikte sleutels, maar alleen die met een TTL ingesteld.allkeys-random: Verwijdert willekeurige sleutels.volatile-random: Verwijdert willekeurige sleutels, maar alleen die met een TTL ingesteld.
Voor de meeste caching-gebruiksscenario’s zijn allkeys-lru of allkeys-lfu de beste keuzes, omdat ze de meest relevante data in de cache behouden.
5. Implementatiegids: Redis Caching voor Backend API’s
Laten we de theorie omzetten in praktijk met een concreet voorbeeld van hoe u Redis-caching kunt implementeren in een typische backend API. We gebruiken Python met de redis-py client en FastAPI als webframework, maar de principes zijn van toepassing op elke taal of framework.
5.1 Redis Installatie en Setup
U kunt Redis lokaal installeren (via Homebrew op macOS, apt-get op Linux), via Docker, of gebruikmaken van een beheerde cloudservice:
- Lokaal:
sudo apt-get install redis-server(Linux) ofbrew install redis(macOS). - Docker:
docker run --name my-redis -p 6379:6379 -d redis - Cloud: AWS ElastiCache, Azure Cache for Redis, Google Cloud Memorystore. Deze bieden hoge beschikbaarheid, automatische back-ups en schaalbaarheid.
Zorg ervoor dat de Redis-server draait voordat u verdergaat.
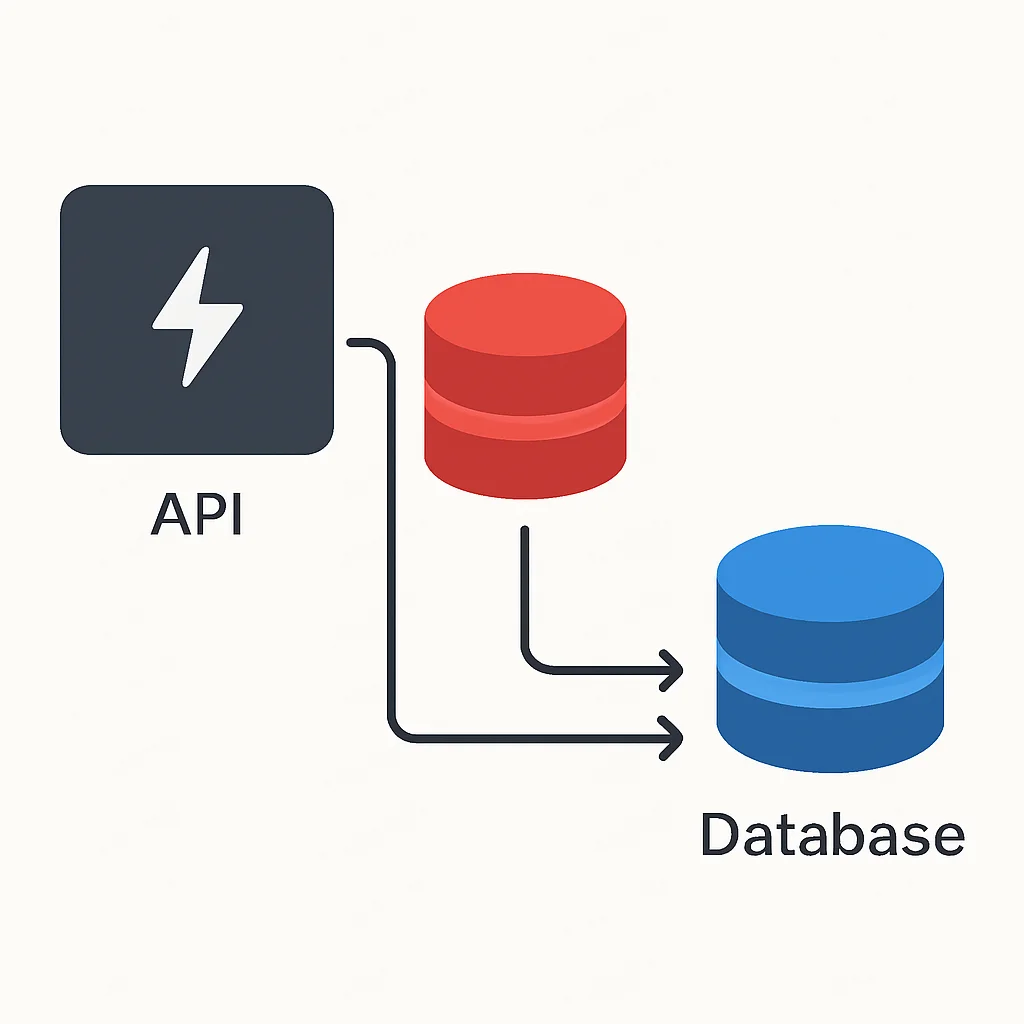
5.2 Basis API Caching Implementatie (Cache-Aside)
Laten we een voorbeeld nemen van een API-endpoint dat productinformatie ophaalt. We cachen de respons van dit endpoint voor 5 minuten (300 seconden) om de databasebelasting te verminderen.
CODE-UITLEG
Deze FastAPI-code toont een Cache-Aside strategie. De API controleert eerst Redis; bij een cache-hit wordt de gecachete data direct geretourneerd. Bij een cache-miss wordt de data uit de “database” (gesimuleerd) gehaald, gecachet en geretourneerd.
from fastapi import FastAPI, HTTPException
import redis
import json
import time
app = FastAPI()
r = redis.Redis(host='localhost', port=6379, db=0)
# Gesimuleerde database
fake_db = {
"prod_001": {"id": "prod_001", "name": "Innovatie Widget X", "price": 129.99, "description": "Een revolutionaire widget voor de moderne gebruiker.", "stock": 500},
"prod_002": {"id": "prod_002", "name": "Ultra Gadget Pro", "price": 299.00, "description": "De ultieme gadget voor professionals.", "stock": 250},
"prod_003": {"id": "prod_003", "name": "Basic USB-kabel", "price": 9.50, "description": "Hoogwaardige USB-kabel.", "stock": 5000}
}
CACHE_TTL = 300 # Cache voor 5 minuten (300 seconden)
@app.get("/products/{product_id}")
async def get_product(product_id: str):
cache_key = f"product:{product_id}"
# 1. Probeer data uit de cache te halen
cached_data = r.get(cache_key)
if cached_data:
print(f"Cache Hit voor {product_id}")
return json.loads(cached_data)
print(f"Cache Miss voor {product_id}. Ophalen uit DB...")
# 2. Data niet in cache, haal op uit 'database' (simulatie)
time.sleep(0.1) # Simuleer database latency
product = fake_db.get(product_id)
if not product:
raise HTTPException(status_code=404, detail="Product niet gevonden")
# 3. Cache de data en retourneer
r.setex(cache_key, CACHE_TTL, json.dumps(product))
print(f"Data voor {product_id} gecachet met TTL van {CACHE_TTL} seconden.")
return product
@app.put("/products/{product_id}")
async def update_product_stock(product_id: str, new_stock: int):
if product_id not in fake_db:
raise HTTPException(status_code=404, detail="Product niet gevonden")
# Update in 'database'
fake_db[product_id]["stock"] = new_stock
print(f"Product {product_id} voorraad bijgewerkt naar {new_stock} in DB.")
# Invalideer de cache voor dit product
cache_key = f"product:{product_id}"
r.delete(cache_key)
print(f"Cache voor {product_id} geïnvalideerd.")
return {"message": "Product voorraad succesvol bijgewerkt en cache geïnvalideerd."}
# Om de applicatie te draaien: uvicorn main:app --reload
# Testen:
# GET http://localhost:8000/products/prod_001 (Eerste keer is Cache Miss, daarna Cache Hit)
# PUT http://localhost:8000/products/prod_001?new_stock=450 (Invalideert cache)
# GET http://localhost:8000/products/prod_001 (Weer Cache Miss, nieuwe data)
Dit voorbeeld toont een basale Cache-Aside implementatie. Bij een GET-aanvraag wordt eerst de cache geraadpleegd. Als de data daar niet is, wordt deze uit de database gehaald, in de cache geplaatst met een TTL, en vervolgens geretourneerd. Bij een PUT-aanvraag (update) wordt de data in de “database” bijgewerkt en de corresponderende cache-sleutel handmatig verwijderd om stale data te voorkomen.
5.3 Geavanceerde Caching Patronen
Naast basis-API-responscaching zijn er diverse geavanceerde patronen waarin Redis excelleert:
Sessie Caching
Sessiestatus van gebruikers opslaan in Redis in plaats van in het geheugen van de applicatieserver of een database. Essentieel voor schaalbare, stateless microservices-architecturen.
Full-Page Caching (FPC)
Volledige HTML-pagina’s cachen voor anonieme gebruikers. Bij een aanvraag wordt eerst gekeken of de pagina in de cache staat; zo ja, wordt deze direct geserveerd zonder de backend te raken. Dit verbetert de responstijd drastisch.
Object Caching
Specifieke objecten of resultaten van complexe berekeningen cachen. Bijvoorbeeld, de resultaten van een zware rapportagequery die lang duurt om te genereren.
Rate Limiting
Gebruik Redis’ atomiciteit en incrementele commando’s (INCR) om het aantal aanvragen per gebruiker of IP-adres binnen een bepaalde tijd te beperken, ter bescherming tegen misbruik en DDoS-aanvallen.
5.4 Monitoring van Redis Prestaties
Het monitoren van uw Redis-instantie is cruciaal om de effectiviteit van uw caching-strategie te beoordelen en potentiële problemen te identificeren. Belangrijke metrics om bij te houden zijn:
- Cache Hit Ratio: Het percentage aanvragen dat succesvol uit de cache wordt gehaald. Een hoge hit ratio (bijv. >90%) duidt op effectieve caching.
- Geheugengebruik: Hoeveel geheugen Redis verbruikt. Dit helpt bij het detecteren van geheugenlekkages of wanneer u moet opschalen.
- Latency: De tijd die Redis nodig heeft om commando’s uit te voeren. Hoge latency kan duiden op overbelasting van de server.
- Verbindingen: Het aantal actieve clientverbindingen.
- Evicties: Hoe vaak Redis sleutels uit het geheugen verwijdert om ruimte te maken. Veel evicties kunnen betekenen dat uw cache te klein is of dat uw TTL’s te kort zijn.
Tools zoals Redis Insight, Prometheus met Grafana, of cloud-specifieke monitoringdiensten (CloudWatch voor AWS ElastiCache) kunnen u helpen deze metrics te visualiseren en te analyseren. Door deze metrics te monitoren, kunt u uw caching-strategie continu optimaliseren en de prestaties van uw backend applicaties garanderen.
Veelgestelde Vragen (FAQ)
Q. Wat is het grootste voordeel van Redis ten opzichte van een traditionele database voor caching?
Het grootste voordeel van Redis voor caching is de uitzonderlijke snelheid, omdat het een in-memory datastructuurserver is. Dit resulteert in microseconden responstijden, wat veel sneller is dan de milliseconden latency van traditionele databases die primair geoptimaliseerd zijn voor persistentie op schijf.
Q. Hoe voorkom ik dat mijn cache verouderde gegevens (stale data) bevat?
U kunt stale data voorkomen door een Time-To-Live (TTL) in te stellen voor cache-items, handmatig cache-items te invalideren na een update in de database, of door geavanceerdere strategieën zoals Publish/Subscribe-mechanismen te gebruiken om wijzigingen te communiceren en caches te verversen.
Q. Wat is een ‘cache stampede’ en hoe kan ik dit mitigeren met Redis?
Een cache stampede treedt op wanneer veel gelijktijdige aanvragen een cache miss ervaren voor hetzelfde item, wat leidt tot een overbelasting van de onderliggende database. Dit kan worden gemitigeerd met Redis door gedistribueerde locks te gebruiken, probabilistische caching (jitter), of een ‘refresh-ahead’ strategie waarbij de cache proactief wordt ververst.
Q. Welke Redis-datastructuur is het meest geschikt voor het cachen van gebruikersprofielen?
Voor het cachen van gebruikersprofielen is de Redis Hash-datastructuur ideaal. Het stelt u in staat om elk veld van het profiel (bijv. naam, e-mail, adres) als een afzonderlijk veld in de hash op te slaan, waardoor efficiënte updates van individuele velden mogelijk zijn zonder het hele object opnieuw te hoeven serialiseren en cachen.
Q. Is Redis persistent, of verliest het alle data bij een herstart?
Redis is primair een in-memory database, maar het biedt wel persistentie-opties. U kunt RDB-snapshots (point-in-time snapshots) of AOF-logging (Append-Only File, logt elke schrijfbewerking) configureren om data op schijf op te slaan. Hierdoor kan Redis de data herstellen na een herstart, wat het “cold start” probleem vermindert.
Afsluiting: De Toekomst van Backend Prestaties met Caching
In deze uitgebreide gids hebben we de cruciale rol van caching in moderne backend-applicaties belicht, met een diepgaande focus op Redis als de voorkeurstechnologie voor prestatieoptimalisatie in 2026. We hebben de fundamentele concepten van caching verkend, de ongeëvenaarde mogelijkheden van Redis’ datastructuren en snelheid geanalyseerd, en diverse geavanceerde caching-strategieën besproken.
Van het aanpakken van stale data en cache stampedes tot het effectief beheren van geheugen en het implementeren van praktische caching-oplossingen, het is duidelijk dat een weloverwogen caching-strategie de ruggengraat vormt van elke schaalbare en responsieve applicatie. De mogelijkheid om miljoenen aanvragen per seconde te verwerken met minimale latency is niet langer een luxe, maar een standaardvereiste voor het succes van digitale producten.
De investering in het begrijpen en implementeren van caching met Redis betaalt zich dubbel en dwars terug in verbeterde gebruikerservaring, lagere operationele kosten en een grotere veerkracht van uw systemen. Terwijl de technologie zich verder ontwikkelt, zullen in-memory datastructuren zoals Redis alleen maar belangrijker worden in het streven naar de ultieme backend-prestaties.
Blijf experimenteren, monitoren en optimaliseren. De wereld van backend-ontwikkeling is constant in beweging, en een proactieve benadering van prestatieoptimalisatie zal u helpen om voorop te blijven in de competitieve digitale arena. Kwonnis blijft u voorzien van de nieuwste inzichten en beste praktijken om uw technologische ambities te verwezenlijken.
Bedankt voor het lezen!
We hopen dat deze gids u waardevolle inzichten heeft gegeven in het verbeteren van uw backend-prestaties met Redis caching.
Vragen of opmerkingen over uw eigen caching-ervaringen? Laat een reactie achter op Kwonnis.com. We horen graag van u!