

Moderne data-architecturen zijn de ruggengraat van datagedreven besluitvorming in 2026 en essentieel voor elke vooruitstrevende organisatie.
Dit artikel duikt diep in de principes, componenten en implementatiestrategieën van moderne data-architecturen, en belicht hoe bedrijven hun concurrentievoordeel kunnen vergroten door effectief gebruik te maken van hun data. We analyseren de evolutie van traditionele systemen naar flexibele, schaalbare architecturen en bieden praktische inzichten voor een succesvolle transformatie.
Inhoudsopgave
01Achtergrond: De Noodzaak van Moderne Data-Architecturen
02Kerninhoud: Evolutie en Principes van Moderne Data-Architecturen
03Componenten van een Robuuste Data-Architectuur
04Implementatie en Best Practices
05Probleemoplossing: Veelvoorkomende Uitdagingen en Oplossingen
06Praktische Toepassing: Casestudies en Succesverhalen
07Conclusie: De Toekomst van Data-Architecturen
Achtergrond: De Noodzaak van Moderne Data-Architecturen

In het huidige digitale tijdperk is data meer dan ooit de drijvende kracht achter zakelijk succes. Organisaties verzamelen enorme hoeveelheden informatie uit diverse bronnen: van klantinteracties en transacties tot IoT-sensoren en sociale media. Het effectief beheren, verwerken en analyseren van deze data is cruciaal voor het verkrijgen van waardevolle inzichten en het nemen van strategische beslissingen.
Traditionele data-architecturen, vaak gebaseerd op relationele databases en on-premise datawarehouses, worstelen om te voldoen aan de eisen van de moderne datalandschap. Ze zijn vaak rigide, schalen slecht en kunnen moeizaam omgaan met de snelheid, variëteit en het volume van big data.
Deze beperkingen leiden tot vertragingen in rapportages, gemiste kansen voor real-time analyses en hogere operationele kosten. Bedrijven die vasthouden aan verouderde structuren lopen het risico achterop te raken ten opzichte van concurrenten die wendbaarder en datagedrevener zijn.
De Evolutie van Data
De afgelopen tien jaar hebben we een exponentiële groei gezien in de hoeveelheid gegenereerde data. Volgens een rapport van IDC zal de wereldwijde datasfeer tegen 2025 naar verwachting 175 zettabytes bereiken. Deze groei wordt gedreven door factoren zoals:
- Internet of Things (IoT): Miljarden verbonden apparaten genereren continu sensordata.
- Digitale Transformatie: Bedrijven digitaliseren processen, wat leidt tot meer data.
- Sociale Media: Gebruikersinteracties genereren enorme hoeveelheden ongestructureerde data.
- Cloud Computing: De adoptie van cloudplatforms maakt het opslaan en verwerken van data op schaal toegankelijker en betaalbaarder.
Het vermogen om deze diverse en omvangrijke datastromen efficiënt te beheren, vormt de kern van moderne data-uitdagingen.
Kerninhoud: Evolutie en Principes van Moderne Data-Architecturen

De verschuiving naar moderne data-architecturen is geen kwestie van het vervangen van één systeem door een ander, maar eerder een fundamentele heroverweging van hoe data wordt verzameld, opgeslagen, verwerkt en geconsumeerd. Deze evolutie is gedreven door de noodzaak van flexibiliteit, schaalbaarheid en de mogelijkheid om zowel gestructureerde als ongestructureerde data te verwerken.
Van Traditioneel naar Modern
Traditionele architecturen waren vaak monolietisch, met een centraal datawarehouse als de enige bron van waarheid. Hoewel effectief voor gestructureerde, batch-verwerkte data, falen ze bij het omgaan met real-time streaming data of semi-gestructureerde/ongestructureerde formaten zoals JSON of logbestanden.
Moderne architecturen omarmen een meer gedistribueerde en gedecentraliseerde aanpak, vaak gebruikmakend van cloud-native technologieën en microservices.
Kernprincipes van Moderne Data-Architecturen
De volgende principes vormen de basis voor een succesvolle moderne data-architectuur:
- Schaalbaarheid: Het vermogen om horizontaal uit te breiden om toenemende datavolumes en verwerkingsbehoeften aan te kunnen, vaak via cloud-oplossingen zoals AWS S3, Azure Data Lake of Google Cloud Storage.
- Flexibiliteit: Ondersteuning voor diverse datatypes (gestructureerd, semi-gestructureerd, ongestructureerd) en verschillende verwerkingsparadigma’s (batch, streaming, real-time).
- Data Governance & Beveiliging: Robuuste mechanismen voor datakwaliteit, privacy, compliancy en toegangsbeheer zijn van het grootste belang in een complexe architectuur.
- Kosten-efficiëntie: Gebruikmaken van pay-as-you-go cloudmodellen en geoptimaliseerde opslaglagen om kosten te beheersen.
- Real-time Mogelijkheden: De capaciteit om data in real-time te verwerken en te analyseren voor directe inzichten en acties.
Een goed ontworpen architectuur faciliteert snelle innovatie en biedt een solide basis voor AI- en machine learning-initiatieven.
Componenten van een Robuuste Data-Architectuur
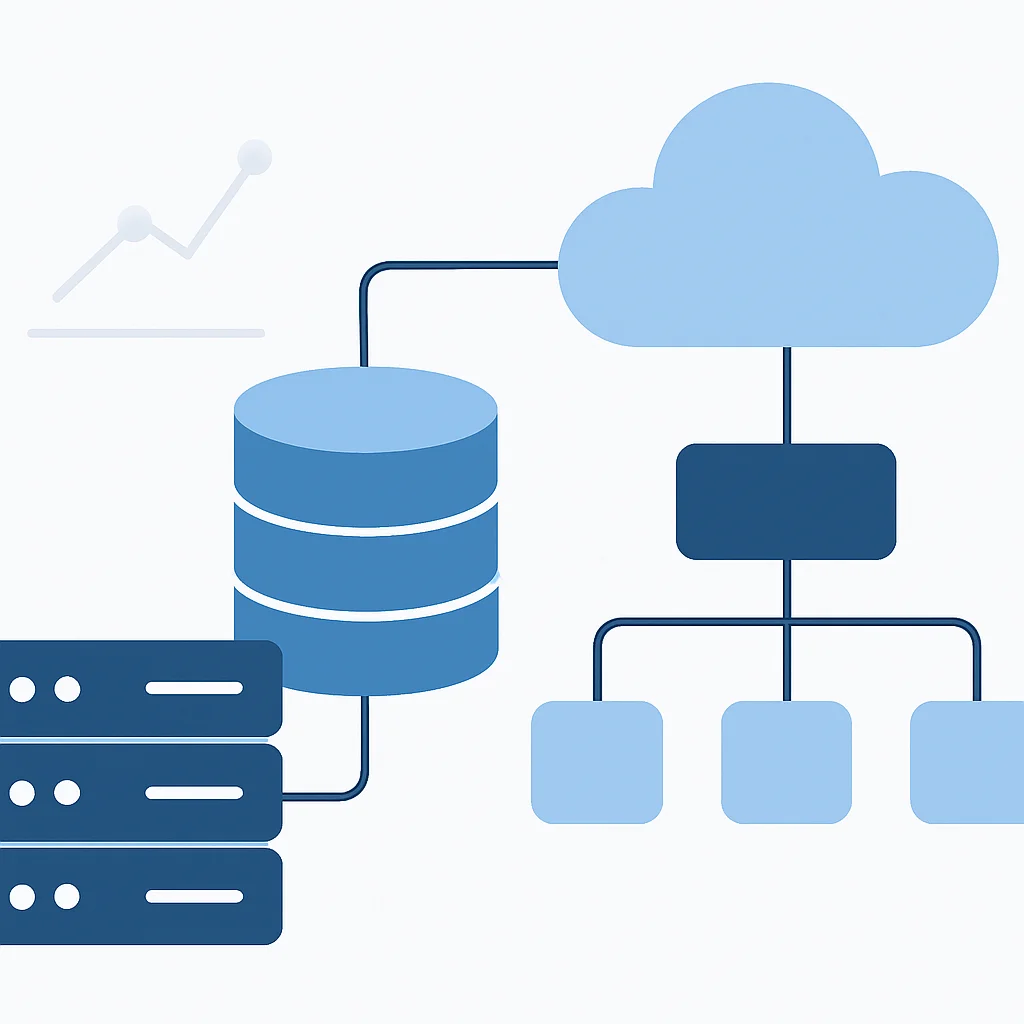
Moderne data-architecturen bestaan uit verschillende met elkaar verbonden componenten die elk een specifieke rol vervullen in de data-levenscyclus. De exacte samenstelling kan variëren, maar de kernbouwstenen blijven consistent.
Data-inname (Ingestion)
Dit is het proces van het verzamelen en importeren van data uit verschillende bronnen. Dit kan batch-gebaseerd zijn (bijv. dagelijkse ETL-processen) of real-time streaming (bijv. IoT-data). Gangbare tools en technologieën zijn:
- Kafka/Pulsar: Voor real-time streamverwerking en messaging.
- AWS Kinesis/Azure Event Hubs/Google Cloud Pub/Sub: Managed services voor streaming data.
- Apache NiFi/Airbyte: Voor flexibele data-integratie en ETL.
Data-opslag (Storage)
Moderne architecturen maken gebruik van een combinatie van opslagoplossingen, afhankelijk van het type data en de toegangsvereisten. Het concept van een data lake is hierbij cruciaal, waar ruwe data in zijn oorspronkelijke formaat wordt opgeslagen.
- Data Lake (Object Storage): Zoals AWS S3, Azure Data Lake Storage, Google Cloud Storage. Opslag van ruwe, ongestructureerde data tegen lage kosten.
- Data Warehouse (Cloud-native): Zoals Snowflake, Google BigQuery, AWS Redshift, Azure Synapse Analytics. Geoptimaliseerd voor gestructureerde analyses en BI.
- NoSQL Databases: Zoals MongoDB, Cassandra, DynamoDB voor specifieke applicatiebehoeften met flexibele schema’s.
Data-verwerking (Processing)
Na opslag moet data worden getransformeerd, verrijkt en gereedgemaakt voor analyse. Dit omvat data cleaning, aggregatie en het toepassen van bedrijfslogica.
- Apache Spark: Een krachtig open-source framework voor big data verwerking (batch en streaming).
- Databricks: Een unified analytics platform gebaseerd op Spark, dat samenwerking en MLOps mogelijk maakt.
- ETL/ELT Tools: Zoals Fivetran, dbt (data build tool) voor data-transformatie in het datawarehouse.
- Serverless Computing: Zoals AWS Lambda, Azure Functions voor event-driven data-verwerking.
Data-analyse en -consumptie
De uiteindelijke stap is het beschikbaar stellen van de verwerkte data aan gebruikers en applicaties voor analyse, rapportage, machine learning en operationele besluitvorming.
- Business Intelligence (BI) Tools: Zoals Tableau, Power BI, Looker voor dashboards en rapportages.
- Machine Learning Platforms: Zoals SageMaker, Azure ML, Google AI Platform voor het bouwen en deployen van ML-modellen.
- API’s: Voor applicaties om programmatisch toegang te krijgen tot data.
De integratie van deze componenten creëert een krachtig ecosysteem dat in staat is om complexe databehoeften te ondersteunen.
Implementatie en Best Practices

De succesvolle implementatie van een moderne data-architectuur vereist meer dan alleen het kiezen van de juiste technologieën. Het is een strategisch proces dat zorgvuldige planning, uitvoering en continue optimalisatie omvat.
Stapsgewijze Aanpak
- Definieer Bedrijfsdoelstellingen: Begin met het begrijpen welke zakelijke problemen moeten worden opgelost en welke inzichten nodig zijn. Dit stuurt de architectuurkeuzes.
- Beoordeel Bestaande Systemen: Identificeer knelpunten en databronnen in de huidige architectuur.
- Ontwerp de Architectuur: Kies de juiste cloudproviders, opslagoplossingen, verwerkingsengines en analysetools. Overweeg een Data Mesh-benadering voor grote organisaties.
- Implementeer in Fasen: Begin klein met een proof-of-concept (PoC) of een minimale levensvatbare architectuur (MVA) en schaal geleidelijk op.
- Monitor en Optimaliseer: Continue monitoring van prestaties, kosten en datakwaliteit is essentieel voor langdurig succes.
Best Practices
- Data Governance Vanaf Dag Eén: Implementeer beleid en processen voor datakwaliteit, beveiliging, privacy en eigenaarschap. Dit omvat metadata management en datakatalogen.
- Kies Cloud-Native Diensten: Profiteer van de schaalbaarheid, elasticiteit en beheerde services die cloudplatforms bieden. Dit vermindert operationele overhead.
- Automatisering is Key: Automatiseer data-inname, transformatie, tests en deployment (CI/CD) om efficiëntie te verhogen en fouten te verminderen.
- Data Mesh en Data Fabric: Overweeg deze geavanceerde concepten voor gedecentraliseerd databeheer en een uniforme toegang tot data in complexe, hybride omgevingen.
Een proactieve benadering van data governance en automatisering is onmisbaar voor een schaalbare en veilige data-omgeving.
Probleemoplossing: Veelvoorkomende Uitdagingen en Oplossingen

Hoewel moderne data-architecturen enorme voordelen bieden, komen er ook specifieke uitdagingen bij kijken. Het aanpakken van deze problemen is cruciaal voor het succes van de implementatie.
Uitdaging 1: Datakwaliteit en Consistentie
Met data uit diverse bronnen is het handhaven van hoge datakwaliteit en consistentie vaak een strijd. Inaccurate of inconsistente data kan leiden tot verkeerde analyses en beslissingen.
Oplossing: Implementeer robuuste data governance-frameworks, inclusief datakwaliteitscontroles (DQC) en dataprofilering. Gebruik tools voor Master Data Management (MDM) om een uniforme weergave van kritieke bedrijfsentiteiten te creëren. Automatiseer datavalidatie en -opschoning bij de innamefase.
Uitdaging 2: Complexiteit en Talenttekort
De veelheid aan technologieën en de complexiteit van gedistribueerde systemen vereisen gespecialiseerde vaardigheden. Het vinden en behouden van talentvolle data-engineers, architecten en wetenschappers is een grote uitdaging.
Oplossing: Investeer in training en ontwikkeling van bestaand personeel. Overweeg het gebruik van managed services en platformen die de complexiteit abstraheren (bijv. Databricks, Snowflake). Werk samen met externe consultants of serviceproviders om kennis en capaciteit op te bouwen. Focus op het opbouwen van een sterke interne data-cultuur.
Uitdaging 3: Kostenbeheersing in de Cloud
Hoewel cloud-diensten flexibel en schaalbaar zijn, kunnen de kosten snel oplopen als ze niet goed worden beheerd. Ongeoptimaliseerde opslag, onnodige compute-uren en inefficiënte data-overdracht kunnen leiden tot onverwachte uitgaven.
Oplossing: Implementeer FinOps-praktijken om kosten te monitoren en te optimaliseren. Gebruik gelaagde opslag (bijv. koude opslag voor zelden gebruikte data). Optimaliseer query’s en verwerkingsjobs om compute-resources efficiënt te gebruiken. Zorg voor gedetailleerde kostenallocatie en rapportage om verbruik per afdeling of project inzichtelijk te maken.
Het proactief aanpakken van deze uitdagingen is essentieel voor het maximaliseren van de ROI van uw data-investeringen.
Praktische Toepassing: Casestudies en Succesverhalen
De theorie is één ding, maar de praktijk laat zien hoe moderne data-architecturen daadwerkelijk waarde creëren voor bedrijven. Laten we kijken naar enkele voorbeelden van succesvolle implementaties.
Casestudy 1: E-commerce Gigant Optimaliseert Klantbeleving
Een toonaangevende e-commerce speler had moeite met het personaliseren van aanbevelingen en het analyseren van klantgedrag in real-time door een verouderd datawarehouse. Ze migreerden naar een cloud-native data lakehouse-architectuur met Databricks en Snowflake.
Resultaten:
- Real-time Personalisatie: Klantaanbevelingen werden 30% accurater door real-time verwerking van browse- en aankoopgedrag.
- Snellere Rapportage: De tijd voor het genereren van belangrijke bedrijfsrapporten verminderde van uren naar minuten.
- Kostenreductie: Door geoptimaliseerde cloud-resources werden de datakosten met 15% verlaagd ten opzichte van de oude infrastructuur.
Casestudy 2: Productiebedrijf Verbetert Operationele Efficiëntie
Een groot productiebedrijf wilde voorspellend onderhoud implementeren voor hun machines om stilstand te minimaliseren. Dit vereiste het verzamelen en analyseren van enorme hoeveelheden sensordata van IoT-apparaten.
Oplossing: Ze bouwden een data-architectuur op basis van AWS IoT Core voor data-inname, AWS Kinesis voor streaming verwerking, en AWS S3 en Amazon Redshift voor opslag en analyse.
Resultaten:
- Minder Stilstand: Voorspellend onderhoud verminderde onverwachte machine stilstand met 25%.
- Verhoogde Productiviteit: De totale productiviteit steeg met 10% door efficiënter onderhoud en geoptimaliseerde operaties.
- Nieuwe Inzichten: Identificatie van patronen die voorheen onzichtbaar waren, leidend tot productverbeteringen.
Deze voorbeelden tonen aan dat een doordachte data-architectuur direct bijdraagt aan bedrijfsresultaten en innovatie.
Conclusie: De Toekomst van Data-Architecturen
Moderne data-architecturen zijn geen luxe meer, maar een absolute noodzaak voor organisaties die willen overleven en floreren in het datatijdperk van 2026 en daarna. Ze stellen bedrijven in staat om de complexiteit van big data te temmen, real-time inzichten te genereren en zich snel aan te passen aan veranderende marktomstandigheden.
De verschuiving naar cloud-native, gedistribueerde en flexibele architecturen is onomkeerbaar. Bedrijven die investeren in deze transformatie zien niet alleen verbeterde operationele efficiëntie, maar ook een verhoogd vermogen om te innoveren en nieuwe, datagedreven producten en diensten te ontwikkelen.
De toekomst ligt in nog intelligentere, geautomatiseerde en zelf-optimaliserende data-ecosystemen.
Vooruitblik
We kunnen verwachten dat de volgende trends de data-architectuur verder zullen vormgeven:
- Nog Meer Automatisering: Van data-inname tot model deployment, AI en ML zullen een grotere rol spelen in het automatiseren van datataken.
- Data Mesh en Data Fabric Dominantie: Voor grote, gedecentraliseerde organisaties zullen deze architecturen de norm worden voor schaalbaar databeheer.
- Edge Computing Integratie: Verwerking van data dichter bij de bron (IoT-apparaten, sensoren) om latency te verminderen en bandbreedte te besparen.
- Verhoogde Focus op Data Ethiek en Responsible AI: Naarmate data en AI krachtiger worden, neemt de behoefte aan ethische richtlijnen en transparantie toe.
Door deze trends te omarmen en continu te investeren in hun data-infrastructuur, kunnen organisaties een duurzaam concurrentievoordeel opbouwen en zich voorbereiden op de datagedreven toekomst.
Begin vandaag nog met het transformeren van uw data-landschap.
Neem contact op met Kwonnis voor een diepgaande analyse van uw huidige data-architectuur en advies over de stappen die nodig zijn om een toekomstbestendige, schaalbare en inzichtgedreven data-omgeving te creëren. Uw data is uw grootste troef – laat Kwonnis u helpen deze optimaal te benutten.