

SAMENVATTING
SQL vs NoSQL: De Juiste Database Kiezen voor Jouw Project in 2026
Een diepgaande vergelijking tussen SQL en NoSQL databases om developers te helpen de optimale datastore te selecteren voor hun backend-applicaties.
Keywords: SQL, NoSQL, Database Architectuur
ACHTERGROND
Achtergrond en Belang van Databasekeuze in 2026
In de snel evoluerende wereld van softwareontwikkeling, en in het bijzonder backend-systemen, is de keuze van de juiste database een van de meest cruciale beslissingen die een projectteam moet nemen. Deze keuze beïnvloedt niet alleen de prestaties en schaalbaarheid van een applicatie, maar ook de ontwikkelingssnelheid, onderhoudbaarheid en zelfs de kosten op lange termijn. In 2026, met de exponentiële groei van data en de toenemende complexiteit van applicaties, is de traditionele dichotomie tussen SQL (relationele) en NoSQL (niet-relationele) databases relevanter dan ooit.
Decennia lang waren relationele databases de onbetwiste standaard. Hun robuuste structuur, gegarandeerde data-integriteit via ACID-eigenschappen (Atomiciteit, Consistentie, Isolatie, Duurzaamheid) en de kracht van SQL als querytaal maakten ze ideaal voor transactionele systemen zoals financiële applicaties en e-commerce platforms. Echter, de opkomst van het internet, big data en gedistribueerde systemen heeft de grenzen van deze traditionele architectuur blootgelegd, met name op het gebied van horizontale schaalbaarheid en flexibiliteit voor ongestructureerde data.
Dit is waar NoSQL-databases hun intrede deden. Ontworpen om de beperkingen van relationele databases aan te pakken, bieden NoSQL-oplossingen een verscheidenheid aan datamodellen (document, key-value, column-family, graph) die beter geschikt zijn voor grote volumes, hoge snelheid en ongestructureerde of semi-gestructureerde data. Ze zijn vaak geoptimaliseerd voor horizontale schaalbaarheid en hoge beschikbaarheid, wat ze populair maakt voor real-time applicaties, IoT en sociale netwerken.
KERNPUNT
De databasekeuze in 2026 is geen kwestie van ‘goed’ of ‘fout’, maar van het selecteren van de optimale datastore die aansluit bij de specifieke vereisten van het project, zoals data-structuur, schaalbaarheid, consistentiebehoeften en budget.
Deze blogpost van Kwonnis duikt diep in de architectuur, sterke en zwakke punten van zowel SQL als NoSQL databases. We zullen concrete voorbeelden, cijfers en use-cases bespreken om u te helpen een weloverwogen beslissing te nemen. Ons doel is om technisch jargon te vertalen naar begrijpelijke taal, zodat u, ongeacht uw technische achtergrond, de nuances van elke benadering kunt begrijpen en de beste keuze kunt maken voor uw backend-projecten in 2026.

KERNINHOUD
Relationele Databases (SQL): Structuur, Sterkten en Zwakten
Relationele databases, gebaseerd op het relationele model van Edgar F. Codd uit de jaren ’70, organiseren data in tabellen die bestaan uit rijen en kolommen. Deze tabellen zijn met elkaar verbonden via relaties (JOINs), wat zorgt voor een gestructureerde en consistente opslag van informatie. SQL (Structured Query Language) is de standaardtaal voor het bevragen en manipuleren van data in deze systemen.
De Principes van SQL Databases
De kern van relationele databases ligt in hun strikte schema en de naleving van de ACID-eigenschappen:
• Atomiciteit: Een transactie wordt ofwel volledig uitgevoerd, ofwel helemaal niet. Er is geen gedeeltelijke uitvoering mogelijk.
• Consistentie: Een transactie brengt de database van de ene geldige staat naar de andere, waarbij alle gedefinieerde regels en beperkingen (constraints) worden gehandhaafd.
• Isolatie: Gelijktijdige transacties worden geïsoleerd uitgevoerd, alsof ze sequentieel plaatsvinden, om conflicten te voorkomen.
• Duurzaamheid: Eenmaal vastgelegde transacties blijven permanent, zelfs bij systeemfouten of stroomuitval.
Deze eigenschappen maken SQL-databases uitermate geschikt voor scenario’s waar data-integriteit en betrouwbaarheid van het grootste belang zijn. Een ander kenmerk is het vaste schema, waarbij de structuur van de data (kolommen, datatypes) vooraf wordt gedefinieerd. Dit zorgt voor voorspelbaarheid en dwingt consistentie af, maar kan ook leiden tot minder flexibiliteit bij snelle schemawijzigingen.
Voordelen van SQL Databases
Voordelen
✓ Sterke Consistentie en Data-integriteit: ACID-eigenschappen garanderen betrouwbare transacties.
✓ Volwassenheid en Grote Community: Jarenlange ontwikkeling heeft geleid tot stabiele, goed gedocumenteerde systemen met veel tools en expertise.
✓ Complexe Query’s en JOINs: SQL is krachtig voor het uitvoeren van complexe query’s over meerdere gerelateerde tabellen.
✓ Standaardisatie: SQL is een gestandaardiseerde taal, wat de leercurve en overdraagbaarheid vergemakkelijkt.
✓ Transactiebeheer: Uitstekend voor applicaties die strikte transactiegaranties vereisen, zoals bankieren of voorraadbeheer.
Nadelen
✗ Verticale Schaalbaarheid: Traditioneel schalen SQL-databases verticaal (meer RAM, CPU), wat duur en beperkt is.
✗ Stijf Schema: Wijzigingen in het schema kunnen complex en tijdrovend zijn, vooral bij grote databases.
✗ Prestaties bij Grote Datahoeveelheden: JOIN-operaties kunnen traag worden bij enorme datasets over gedistribueerde systemen.
✗ Minder geschikt voor Ongestructureerde Data: Niet optimaal voor het opslaan van flexibele, ongestructureerde data zoals JSON-documenten.
Populaire SQL Databases en Use Cases
Enkele van de meest gebruikte SQL databases in 2026 zijn:
• PostgreSQL: Open-source, object-relationele database bekend om zijn robuustheid, uitbreidbaarheid en naleving van SQL-standaarden. Vaak de voorkeur voor complexe data-integriteit en geografische data.
• MySQL: De meest populaire open-source relationele database, veel gebruikt voor webapplicaties (LAMP-stack) vanwege zijn snelheid en eenvoud. Eigendom van Oracle.
• Oracle Database: Commerciële, enterprise-grade database die ongeëvenaarde functies biedt voor complexe bedrijfskritische systemen.
• Microsoft SQL Server: Commerciële database die naadloos integreert met het Microsoft-ecosysteem, populair in enterprise-omgevingen.
Use Case: E-commerce Bestelsysteem
Een klant plaatst een bestelling, wat een reeks transacties omvat: inventaris bijwerken, betaling verwerken, orderhistorie aanmaken. Hier is ACID-consistentie essentieel om ervoor te zorgen dat elke bestelling correct en volledig wordt afgehandeld, zelfs bij gelijktijdige aankopen.
CODE-UITLEG
Dit SQL-voorbeeld toont een complexe query die de bestelgeschiedenis van een klant ophaalt, inclusief de producten die ze hebben gekocht en de bijbehorende categorieën. Het maakt gebruik van JOIN-clausules om data uit meerdere tabellen te combineren, wat een kracht is van relationele databases.
SELECT
o.order_id,
o.order_date,
c.first_name,
c.last_name,
p.product_name,
p.price,
cat.category_name
FROM
orders o
JOIN
customers c ON o.customer_id = c.customer_id
JOIN
order_items oi ON o.order_id = oi.order_id
JOIN
products p ON oi.product_id = p.product_id
JOIN
categories cat ON p.category_id = cat.category_id
WHERE
c.customer_id = 101
ORDER BY
o.order_date DESC;
KERNPUNT
SQL-databases zijn de gouden standaard voor toepassingen die sterke data-consistentie, complexe relationele queries en gegarandeerde transacties vereisen. Ze excelleren in gestructureerde omgevingen waar het schema stabiel is.
KERNINHOUD
Niet-Relationele Databases (NoSQL): Flexibiliteit en Schaalbaarheid
NoSQL-databases, een breed scala aan databasetechnologieën, zijn ontworpen om de beperkingen van relationele databases aan te pakken, met name op het gebied van schaalbaarheid en flexibiliteit voor ongestructureerde data. De term “NoSQL” staat voor “Not Only SQL”, wat aangeeft dat ze geen strikte SQL-interface volgen en vaak alternatieve datamodellen gebruiken.
De Principes van NoSQL Databases
In tegenstelling tot SQL, die zich richt op ACID, omarmen veel NoSQL-systemen de BASE-eigenschappen (Basically Available, Soft state, Eventual consistency):
• Basically Available: Het systeem garandeert beschikbaarheid voor query’s; elke aanvraag ontvangt een antwoord, ook al is het niet gegarandeerd de meest recente versie van de data.
• Soft state: De staat van het systeem kan na verloop van tijd veranderen, zelfs zonder input, als gevolg van eventual consistency.
• Eventual consistency: De database wordt uiteindelijk consistent, wat betekent dat als er geen verdere updates plaatsvinden, alle replica’s van de data na verloop van tijd zullen convergeren naar dezelfde waarde.
NoSQL-databases hebben vaak een flexibel of schemaloos ontwerp, wat betekent dat u geen vaste structuur hoeft te definiëren voordat u data opslaat. Dit maakt ze ideaal voor projecten met snel veranderende datavereisten of onvoorspelbare datastructuren.
Typen NoSQL Databases
Er zijn verschillende categorieën NoSQL databases, elk geoptimaliseerd voor specifieke soorten data en use cases:
• Document Databases: Slaan data op in flexibele, semi-gestructureerde documenten (meestal JSON of BSON). Ideaal voor contentmanagementsystemen, productcatalogi en gebruikersprofielen. Voorbeelden: MongoDB, Couchbase.
• Key-Value Stores: De meest eenvoudige NoSQL-databases, die data opslaan als een verzameling sleutel-waarde-paren. Extreem snel voor lees- en schrijfbewerkingen. Ideaal voor caching en sessiebeheer. Voorbeelden: Redis, DynamoDB.
• Column-Family Stores: Organiseren data in rijen en dynamische kolommen. Geoptimaliseerd voor analytische workloads en big data-toepassingen met veel schrijfbewerkingen. Voorbeelden: Cassandra, HBase.
• Graph Databases: Slaan data op in knooppunten (entities) en randen (relaties), waardoor ze uitstekend geschikt zijn voor het modelleren van complexe relaties en sociale netwerken. Voorbeelden: Neo4j, Amazon Neptune.
Voordelen van NoSQL Databases
Voordelen
✓ Horizontale Schaalbaarheid: Eenvoudig uit te schalen door meer servers toe te voegen (sharding), ideaal voor big data en hoge verkeersbelasting.
✓ Flexibel Schema: Geen vooraf gedefinieerd schema, wat snelle iteratie en omgaan met veranderende data-eisen mogelijk maakt.
✓ Hoge Beschikbaarheid en Prestaties: Ontworpen voor hoge doorvoer en lage latentie, vaak met ingebouwde replicatie.
✓ Geschikt voor Ongestructureerde Data: Ideaal voor JSON, XML, afbeeldingen, video’s en andere flexibele dataformaten.
✓ Kostenbesparend: Horizontale schaalbaarheid maakt het mogelijk om goedkopere commodity hardware te gebruiken.
Nadelen
✗ Eventual Consistency: Kan leiden tot complexiteit bij het omgaan met data die onmiddellijke consistentie vereist.
✗ Minder Volwassenheid: Sommige NoSQL-systemen zijn jonger en hebben kleinere communities en minder tools dan SQL.
✗ Beperkte JOIN-functionaliteit: Complexe relaties tussen data zijn vaak moeilijker te bevragen zonder JOINs.
✗ Minder Standaardisatie: Geen universele querytaal zoals SQL, wat de leercurve kan verhogen bij het wisselen tussen systemen.
Use Case: Real-time Gebruikersprofielen en Personalisatie
Een sociale mediaplatform moet miljoenen gebruikersprofielen opslaan, elk met unieke, dynamische attributen (posts, likes, volgers). De data-structuur kan snel veranderen. Een documentdatabase zoals MongoDB is ideaal vanwege zijn flexibele schema en horizontale schaalbaarheid, waardoor het snel kan inspelen op veranderende behoeften en hoge verkeersbelasting.
CODE-UITLEG
Dit JavaScript-voorbeeld toont een query in MongoDB om gebruikersprofielen te zoeken die aan bepaalde criteria voldoen en vervolgens een nieuw veld toe te voegen aan een subset van deze profielen. De flexibiliteit van documenten maakt het eenvoudig om JSON-achtige data op te slaan en te manipuleren zonder dat een schemawijziging nodig is.
// Voorbeeld: MongoDB query om gebruikersprofielen te vinden en te updaten
db.users.find(
{
"preferences.newsletter": true,
"last_login": { "$gte": new Date("2026-01-01T00:00:00Z") }
}
).forEach(function(user) {
// Voeg een nieuw veld toe of update een bestaand veld
db.users.updateOne(
{ "_id": user._id },
{ "$set": { "status": "active_subscriber", "updated_at": new Date() } }
);
});
// Een voorbeeld van het invoegen van een flexibel document
db.products.insertOne({
name: "Smartphone X",
brand: "TechCorp",
price: 999.99,
specifications: {
screen: "6.7 inch OLED",
camera: "48MP",
battery_mah: 4500
},
reviews: [
{ user: "Alice", rating: 5, comment: "Geweldig toestel!" },
{ user: "Bob", rating: 4, comment: "Batterij valt wat tegen." }
],
// Dit veld is optioneel en hoeft niet in elk document voor te komen
discount_percentage: 10
});
KERNPUNT
NoSQL-databases blinken uit in scenario’s die horizontale schaalbaarheid, flexibele schema’s en de verwerking van grote hoeveelheden ongestructureerde data vereisen. Ze zijn ideaal voor moderne, gedistribueerde applicaties.
KERNINHOUD
SQL vs NoSQL: Een Vergelijkende Analyse
Nu we de individuele kenmerken van SQL en NoSQL hebben besproken, is het tijd om ze direct met elkaar te vergelijken. De keuze hangt vaak af van de specifieke projectvereisten en de aard van de data die u beheert. Hieronder een gedetailleerde vergelijkingstabel.
Vergelijkingstabel: SQL vs NoSQL
De keuze tussen SQL en NoSQL is vaak een afweging tussen consistentie en schaalbaarheid, bekend als het CAP-theorema. Dit theorema stelt dat een gedistribueerd datastore systeem slechts twee van de volgende drie eigenschappen tegelijkertijd kan garanderen: Consistentie (Consistency), Beschikbaarheid (Availability) en Partitietolerantie (Partition tolerance). Relationele databases prioriteren Consistentie en Beschikbaarheid over Partitietolerantie (CA), terwijl veel NoSQL-databases Beschikbaarheid en Partitietolerantie prioriteren over sterke Consistentie (AP).
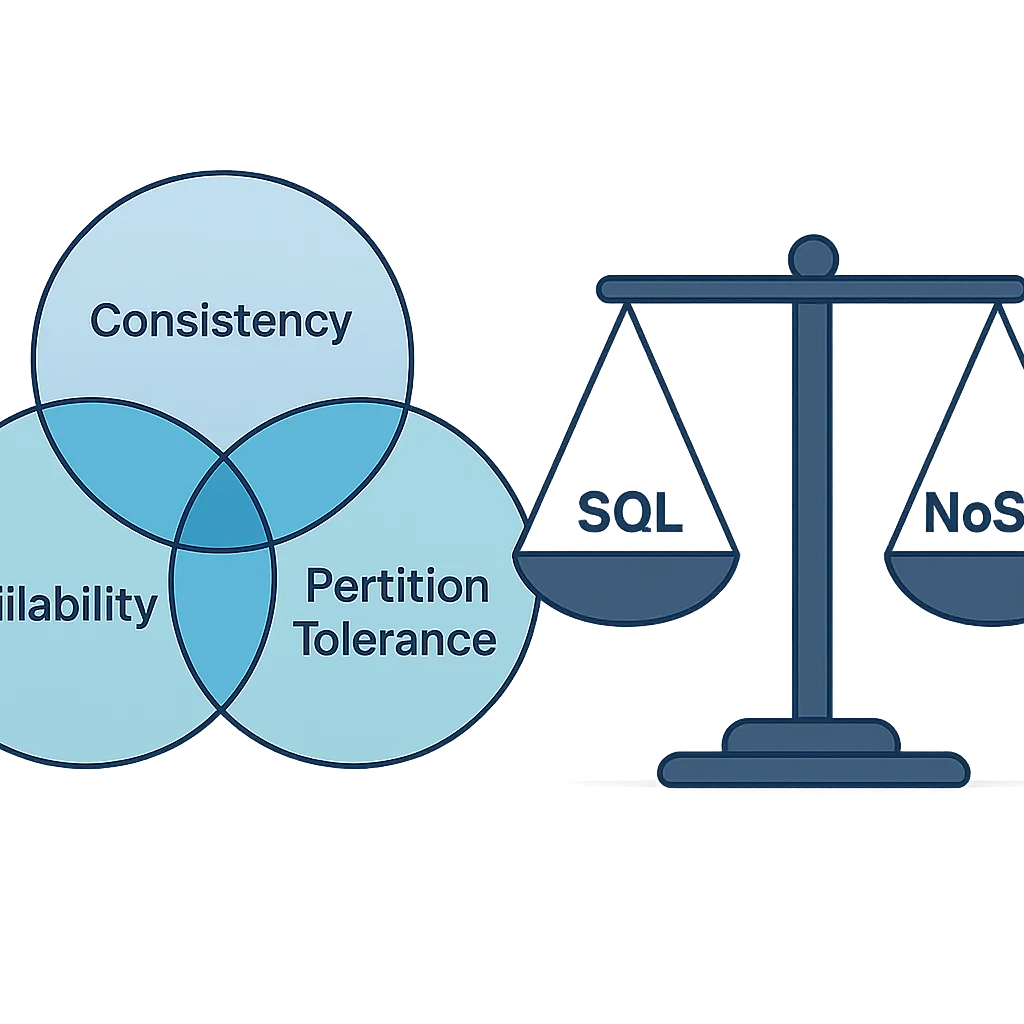
KERNPUNT
De fundamentele afweging tussen SQL en NoSQL draait om het CAP-theorema: moet uw systeem absolute consistentie garanderen (SQL) of is hoge beschikbaarheid en tolerantie voor netwerkpartities belangrijker, zelfs ten koste van onmiddellijke consistentie (NoSQL)?
PROBLEEMOPLOSSING
Probleemoplossing: Schaalbaarheid en Consistentie Uitdagingen
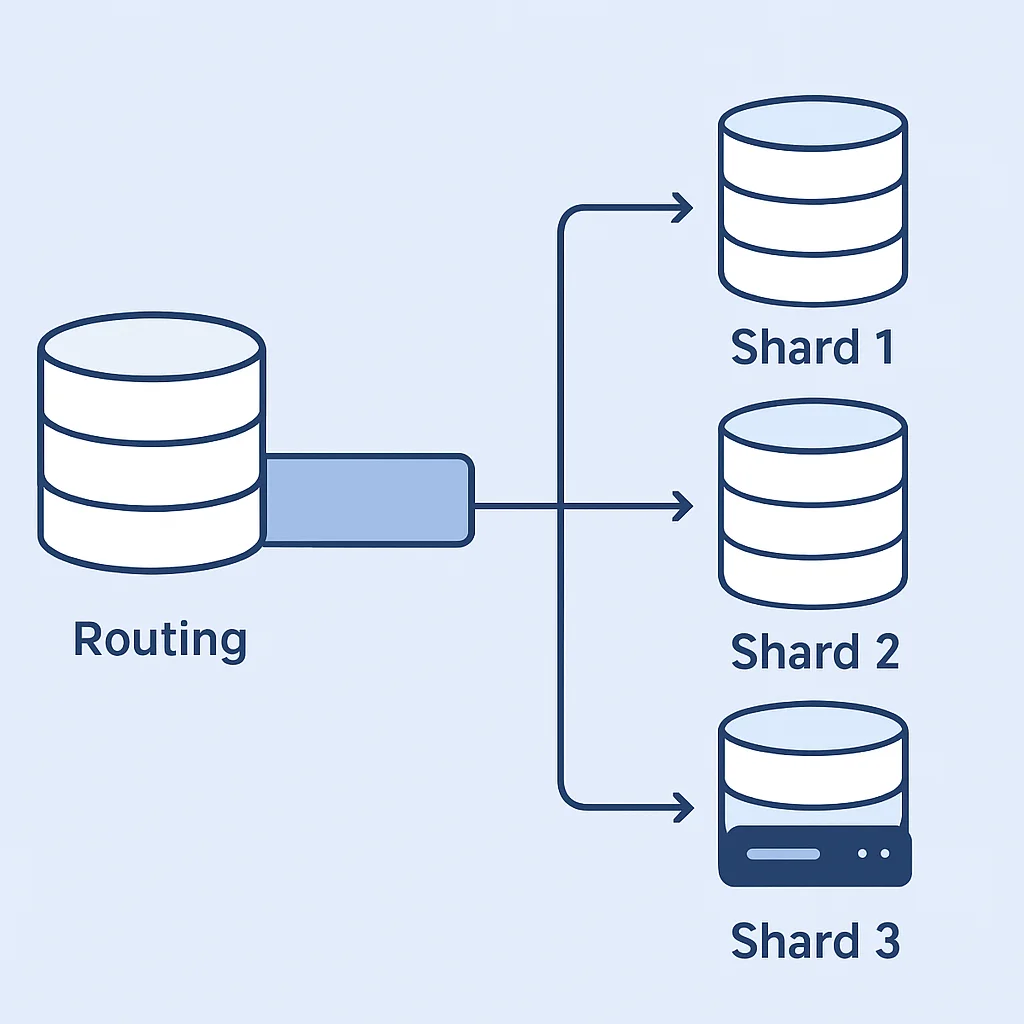
KERNPUNT
Schaalbaarheid en consistentie zijn complexe domeinen. Zowel SQL als NoSQL hebben mechanismen om hun inherente zwakke punten aan te pakken, maar dit vereist vaak zorgvuldige architectuur en implementatie op applicatieniveau.
PRAKTISCHE TOEPASSING
Praktische Toepassing: Wanneer Welke Database Kiezen?
De beslissing voor SQL of NoSQL is zelden zwart-wit. Het hangt af van een combinatie van factoren die uniek zijn voor elk project. Hier zijn richtlijnen voor wanneer u welke technologie moet overwegen.
Wanneer kiest u SQL (Relationele Database)?
Ideaal voor Gestructureerde, Transactionele Data
Complexe Transacties: Voor systemen die ACID-eigenschappen absoluut vereisen, zoals financiële applicaties, bankieren, verzekeringen of complexe ERP-systemen. Denk aan een banktransactie waarbij geld van de ene rekening wordt afgeschreven en op de andere wordt bijgeschreven: dit moet atomair en consistent zijn.
Gestructureerde Data: Wanneer uw data een duidelijk, voorspelbaar schema heeft dat naar verwachting niet drastisch zal veranderen. Bijvoorbeeld gebruikersgegevens, productcatalogi met vaste attributen, of bestelgegevens in een e-commerce systeem.
Complexe Query’s en Rapportage: Als u vaak complexe JOIN-operaties moet uitvoeren over meerdere tabellen voor analytische rapportage of business intelligence. Een voorbeeld is het analyseren van verkooptrends per regio en productcategorie over de afgelopen vijf jaar.
Volwassenheid en Tools: Wanneer een uitgebreid ecosysteem van tools, ervaren ontwikkelaars en bewezen best practices van belang zijn. SQL-databases hebben decennia aan ontwikkeling en ondersteuning.
Voorbeelden: Online banking, voorraadbeheersystemen, traditionele CRM-systemen, contentmanagementsystemen (CMS) met vaste contentstructuren.
Wanneer kiest u NoSQL (Niet-Relationele Database)?
Ideaal voor Schaalbare, Flexibele en Ongestructureerde Data
Big Data en Hoge Schaalbaarheid: Voor applicaties die enorme hoeveelheden data moeten verwerken en/of een extreem hoge verkeersbelasting hebben, met de behoefte aan horizontale schaalbaarheid. Denk aan IoT-platforms die miljoenen sensorgegevens per seconde verzamelen, of sociale netwerken met miljarden interacties.
Flexibel Schema: Wanneer de datastructuur onvoorspelbaar is, snel verandert, of wanneer u snel wilt itereren zonder schema-migraties. Een goed voorbeeld zijn gebruikersprofielen op een sociale media-site, waar nieuwe velden (bijv. voorkeuren, badges) continu kunnen worden toegevoegd.
Ongestructureerde/Semi-gestructureerde Data: Voor het opslaan van documenten, JSON-objecten, logs, media-bestanden of andere data die niet netjes in tabellen past. Denk aan een contentmanagementsysteem voor blogs waar posts diverse formaten en metadata kunnen hebben.
Real-time Toepassingen: Voor applicaties die lage latentie en hoge doorvoer vereisen, zoals real-time analyses, personalisatie-engines, gaming of caching-lagen.
Voorbeelden: Content delivery networks (CDN’s), real-time aanbevelingssystemen, gebruikerssessiebeheer, chat-applicaties, big data analytics platforms.
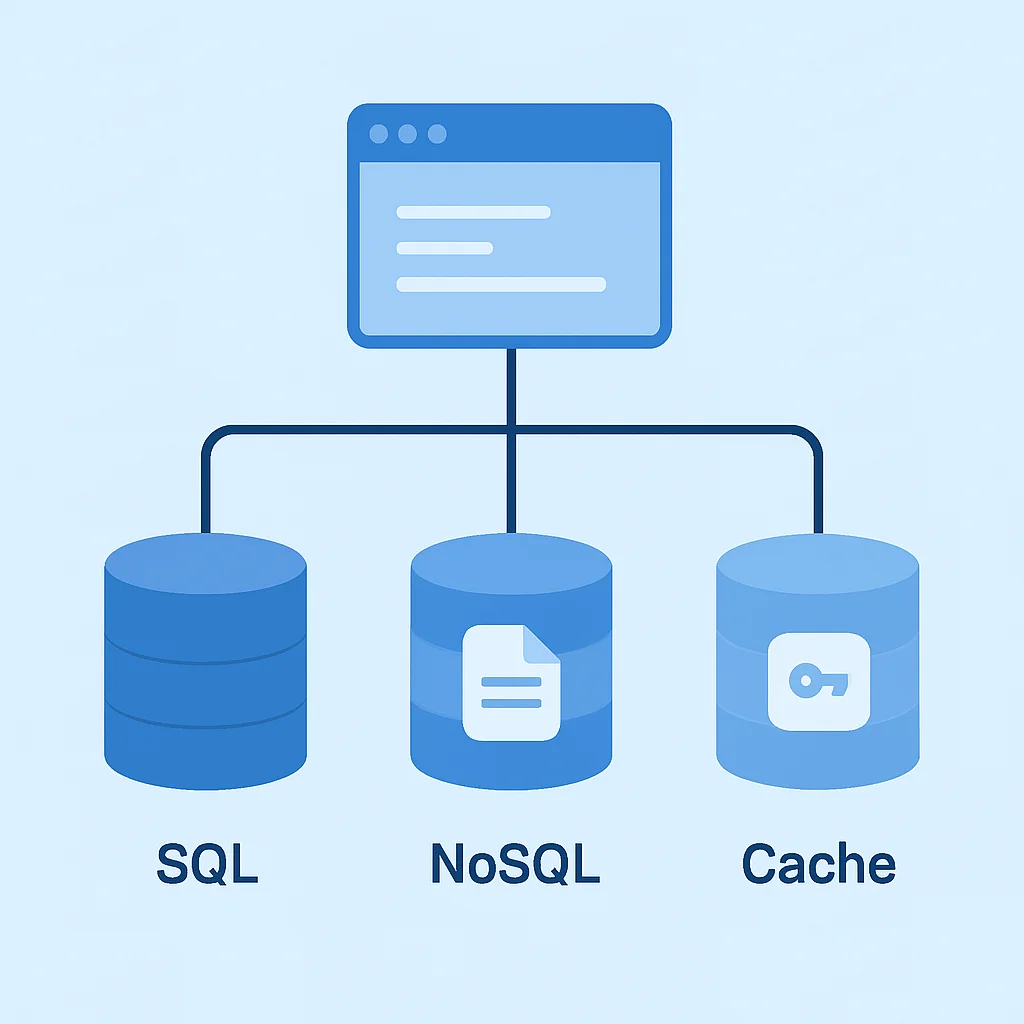
De Hybride Aanpak (Polyglot Persistence)
In 2026 is het steeds gebruikelijker om niet één, maar meerdere databasetypen binnen één applicatie-architectuur te gebruiken, een concept dat bekend staat als Polyglot Persistence. Dit betekent dat u de beste database voor elke specifieke taak kiest.
Bijvoorbeeld:
• Een SQL-database (bijv. PostgreSQL) voor de kern transactionele data (gebruikers, bestellingen, betalingen).
• Een documentdatabase (bijv. MongoDB) voor gebruikersprofielen met flexibele attributen en content (blogposts, recensies).
• Een key-value store (bijv. Redis) voor caching, sessiebeheer en real-time leaderboards.
• Een graph database (bijv. Neo4j) voor het modelleren van complexe relaties zoals sociale connecties of aanbevelingssystemen.
KERNPUNT
De hybride aanpak (Polyglot Persistence) is vaak de meest pragmatische oplossing in complexe projecten van 2026, waarbij de unieke sterke punten van zowel SQL als NoSQL databases worden benut voor verschillende aspecten van de applicatie.
Deze strategie biedt optimale prestaties, schaalbaarheid en flexibiliteit, maar introduceert ook complexiteit in het beheer en de ontwikkeling. Het vereist een goed doordacht architectuurontwerp en een team met expertise in verschillende databasetechnologieën.
FAQ
Veelgestelde Vragen (FAQ)
Q. Wat is het grootste verschil tussen SQL en NoSQL?
Het grootste verschil ligt in hun datamodel en schaalbaarheid. SQL-databases gebruiken een strikt, relationeel schema en schalen primair verticaal, terwijl NoSQL-databases flexibele schema’s en diverse datamodellen hebben en ontworpen zijn voor horizontale schaalbaarheid.
Q. Welke database is beter voor een startup in 2026?
Voor een startup in 2026 hangt de keuze af van de verwachte datagroei en schemaflexibiliteit. Als het schema waarschijnlijk veel zal veranderen en snelle iteratie nodig is, kan NoSQL (bijv. MongoDB) voordelig zijn. Voor applicaties met complexe, consistente transacties is SQL (bijv. PostgreSQL) vaak een betere start.
Q. Kan ik zowel SQL als NoSQL in één project gebruiken?
Absoluut. Dit wordt ‘Polyglot Persistence’ genoemd en is een veelgebruikte aanpak in 2026. U kunt verschillende databasetechnologieën gebruiken voor verschillende delen van uw applicatie, waarbij u de sterke punten van elk type database benut voor specifieke taken.
Q. Zijn NoSQL-databases altijd sneller dan SQL-databases?
Niet per se. Hoewel NoSQL vaak uitblinkt in lees-/schrijfsnelheid voor grote, gedistribueerde datasets en specifieke querypatronen, kunnen SQL-databases extreem efficiënt zijn voor complexe join-operaties en kleinere, gestructureerde datasets. De “snelheid” hangt sterk af van de use case en de optimalisatie.
Conclusie en Toekomstperspectief
De keuze tussen SQL en NoSQL is een fundamentele architecturale beslissing die verregaande gevolgen heeft voor de ontwikkeling, prestaties en schaalbaarheid van uw applicatie. In 2026 is er geen ‘one-size-fits-all’ oplossing. De ideale database is diegene die het beste past bij de specifieke eisen van uw project met betrekking tot datastructuur, consistentiebehoeften, verwachte schaal en budget.
SQL-databases blijven de voorkeurskeuze voor systemen die absolute data-integriteit, complexe transacties en gestructureerde data vereisen. NoSQL-databases daarentegen zijn ongeëvenaard voor flexibiliteit, horizontale schaalbaarheid en het verwerken van grote volumes ongestructureerde data. De opkomst van Polyglot Persistence toont aan dat het combineren van verschillende databasetechnologieën vaak de meest effectieve strategie is om de diverse uitdagingen van moderne applicaties aan te gaan.
Kwonnis raadt aan om een grondige analyse uit te voeren van uw datavereisten, toegangspatronen en toekomstige schaalbaarheidsbehoeften voordat u een definitieve beslissing neemt. Overweeg ook de expertise van uw team en de beschikbaarheid van tooling en community-ondersteuning. De database-landschap blijft evolueren, met trends zoals serverless databases, geautomatiseerd databasemanagement en verdere convergentie van SQL- en NoSQL-functionaliteiten. Blijf op de hoogte van deze ontwikkelingen om in de voorhoede van backend-ontwikkeling te blijven.
Bedankt voor het lezen! Vragen? Laat een reactie achter!
