

SAMENVATTING
Explainable AI (XAI) voor Developers: Maak Je Modellen Transparant in 2026
Een praktische gids voor Explainable AI (XAI) technieken die developers helpen hun machine learning modellen te begrijpen en te debuggen.
Keywords: Explainable AI, XAI, Machine Learning
INHOUDSOPGAVE
1 De Noodzaak van Transparantie in AI: Waarom XAI Cruciaal is in 2026
2 Kern XAI Technieken voor Modelinterpretatie
3 Uitdagingen en Oplossingen bij de Implementatie van XAI
4 XAI Praktisch Toepassen in Jouw ML Workflow
5 Conclusie en Toekomstperspectieven van XAI
ACHTERGROND
De Noodzaak van Transparantie in AI: Waarom XAI Cruciaal is in 2026
In het snel evoluerende landschap van kunstmatige intelligentie (AI) en machine learning (ML) zijn we getuige van een ongekende adoptie van geavanceerde modellen in uiteenlopende sectoren, van gezondheidszorg tot financiën en autonome systemen. Deze modellen, vooral diepgaande neurale netwerken, blinken uit in het detecteren van complexe patronen en het doen van nauwkeurige voorspellingen. Echter, hun kracht schuilt vaak in hun complexiteit, wat leidt tot het “black-box” probleem: we weten wat de modellen doen, maar niet per se waarom ze het doen.
Deze ondoorzichtigheid vormt een aanzienlijke uitdaging, niet alleen voor de acceptatie door gebruikers en regelgevers, maar ook voor de developers zelf. Hoe kunnen we een model debuggen dat onverwacht gedrag vertoont als we niet begrijpen welke kenmerken of logica tot een specifieke uitkomst hebben geleid? Hoe kunnen we vertrouwen op AI-systemen die levensveranderende beslissingen nemen, zoals bij medische diagnoses of kredietbeoordelingen, als we hun redenering niet kunnen valideren?
“In 2026 is Explainable AI (XAI) niet langer een luxe, maar een absolute noodzaak voor elke developer die serieuze AI-oplossingen bouwt.”
— Kwonnis AI Analyse
Explainable AI (XAI) biedt de oplossing voor dit dilemma. Het omvat een reeks technieken en methodologieën die gericht zijn op het transparant, begrijpelijk en interpreteerbaar maken van AI-systemen. Voor developers betekent dit de mogelijkheid om inzicht te krijgen in de interne werking van hun modellen, de factoren die hun beslissingen beïnvloeden te identificeren, en potentiële vooroordelen of fouten op te sporen en te corrigeren.
De Drijvende Krachten Achter XAI in 2026
Verschillende factoren maken XAI in 2026 onmisbaar:
1. Wettelijke en Ethische Vereisten: De opkomst van regelgeving zoals de Europese AI Act dwingt organisaties om verantwoording af te leggen over hun AI-systemen. Met name bij “hoogrisico AI” is interpreteerbaarheid een kritieke eis. Dit omvat sectoren zoals gezondheidszorg, biometrie, rechtshandhaving en kritieke infrastructuur. Het niet voldoen aan deze eisen kan leiden tot aanzienlijke boetes en reputatieschade. Ethische overwegingen, zoals het voorkomen van discriminatie en het waarborgen van eerlijkheid, vereisen ook een diepgaand begrip van modelbeslissingen.
2. Verbeterde Debugging en Modelontwikkeling: Voor developers is XAI een krachtig debugging-tool. Als een model onverwachte resultaten levert, kunnen XAI-technieken helpen om de oorzaak snel te achterhalen. Werkt het model op basis van irrelevante kenmerken? Zijn er verborgen correlaties die tot ongewenste vooroordelen leiden? Door deze inzichten te verkrijgen, kunnen developers efficiënter itereren en robuustere, betrouwbaardere modellen bouwen. Volgens een recent onderzoek van Gartner in 2025, rapporteerde 78% van de AI-teams dat XAI de gemiddelde debug-tijd van complexe ML-modellen met minstens 30% heeft verkort.
3. Verhoogd Vertrouwen en Acceptatie: Gebruikers, stakeholders en het management zijn eerder geneigd AI-systemen te vertrouwen en te accepteren als ze de onderliggende logica kunnen begrijpen. Dit is vooral van belang in sectoren waar menselijke expertise en intuïtie cruciaal zijn. Een arts zal eerder een AI-diagnose accepteren als de AI kan uitleggen waarom het tot die conclusie is gekomen, bijvoorbeeld door relevante symptomen en testresultaten te benadrukken.
4. Optimalisatie van Bedrijfsprocessen: XAI kan ook leiden tot waardevolle zakelijke inzichten. Door te begrijpen welke factoren het meest bijdragen aan succesvolle of onsuccesvolle uitkomsten (bijv. klantverloop, productverkoop), kunnen bedrijven hun strategieën optimaliseren. Bijvoorbeeld, een AI die voorspelt welke klanten zullen vertrekken, kan, met XAI, uitleggen dat “recente prijsverhogingen” en “lage klantenservice scores” de belangrijkste triggers zijn, wat directe actiepunten voor het management oplevert.
KERNPUNT
Explainable AI (XAI) is essentieel in 2026 voor het voldoen aan regelgeving, het verbeteren van modeldebugging, het opbouwen van vertrouwen en het genereren van diepere zakelijke inzichten. Het stelt developers in staat om van black-box modellen naar transparante, verantwoorde AI-oplossingen te evolueren.
KERNINHOUD
Kern XAI Technieken voor Modelinterpretatie
Om AI-modellen transparant te maken, zijn er verschillende XAI-technieken ontwikkeld. Deze technieken kunnen grofweg worden onderverdeeld in model-agnostische (werken met elk type model) en model-specifieke methoden, en in globale (begrip van het algehele modelgedrag) en lokale (begrip van een individuele voorspelling) verklaringen. We richten ons hier op enkele van de meest populaire en effectieve technieken die developers in 2026 kunnen toepassen.
1. Feature Importance (Kenmerkbelang)
Feature Importance is een van de meest eenvoudige en intuïtieve XAI-technieken. Het kwantificeert de relatieve bijdrage van elk inputkenmerk aan de voorspellingen van een model. Voor modellen zoals beslissingsbomen en ensemble-methoden (Random Forests, Gradient Boosting) is feature importance vaak ingebouwd en gemakkelijk toegankelijk. Het geeft een globaal beeld van welke kenmerken het meest invloedrijk zijn voor het model.
KERNPUNT
Feature Importance geeft een snel en globaal inzicht in de invloed van individuele kenmerken op het model. Hoewel het geen causale verbanden toont, is het een uitstekend startpunt voor modelinterpretatie en feature engineering.
Hoe het werkt: Bij boomgebaseerde modellen wordt feature importance vaak berekend op basis van de mate waarin een kenmerk de onzuiverheid (zoals Gini impurity of entropy) vermindert bij het splitsen van knooppunten. Hoe meer een kenmerk de onzuiverheid vermindert over alle splitsingen, hoe belangrijker het wordt geacht.
CODE-UITLEG
Dit Python-voorbeeld toont hoe je de feature importance van een Random Forest Classifier kunt extraheren met behulp van scikit-learn. We genereren synthetische data en trainen een model, waarna we de belangrijkste kenmerken visualiseren.
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import make_classification
import matplotlib.pyplot as plt
import numpy as np
# 1. Synthetische data genereren
# Stel dat we 5 belangrijke kenmerken hebben en 5 minder belangrijke
X, y = make_classification(n_samples=1000, n_features=10, n_informative=5,
n_redundant=0, n_repeated=0, n_classes=2,
random_state=42)
feature_names = [f'feature_{i}' for i in range(X.shape[1])]
df = pd.DataFrame(X, columns=feature_names)
df['target'] = y
# 2. Random Forest model trainen
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(df[feature_names], df['target'])
# 3. Feature importances ophalen
importances = model.feature_importances_
indices = np.argsort(importances)[::-1] # Sorteer van hoog naar laag
# 4. Visualiseren
plt.figure(figsize=(10, 6))
plt.title("Feature Importance in Random Forest Classifier")
plt.bar(range(X.shape[1]), importances[indices], align="center", color="#667eea")
plt.xticks(range(X.shape[1]), [feature_names[i] for i in indices], rotation=90)
plt.xlim([-1, X.shape[1]])
plt.ylabel("Belangrijkheid")
plt.xlabel("Kenmerken")
plt.tight_layout()
# plt.show() # In een echte omgeving zou je dit renderen
print("Top 5 Belangrijkste Kenmerken:")
for i in range(5):
print(f"{feature_names[indices[i]]}: {importances[indices[i]]:.4f}")
Voordelen
✓ Eenvoudig te implementeren en te begrijpen.
✓ Goed voor globale modelinterpretatie.
✓ Ingebouwd in veel populaire ML-bibliotheken.
Nadelen
✗ Kan misleidend zijn bij gecorreleerde kenmerken.
✗ Geeft geen inzicht in de richting van de impact (positief/negatief).
✗ Model-specifiek (vooral voor boommodellen).
2. LIME (Local Interpretable Model-agnostic Explanations)
LIME is een model-agnostische techniek die lokale verklaringen genereert. Dit betekent dat het de voorspelling van een individueel instance uitlegt, in plaats van het hele model. LIME werkt door een lokaal, interpreteerbaar model (zoals een lineaire regressie of een beslissingsboom) te trainen op geperturbeerde versies van het originele data instance, gewogen door hun nabijheid tot het origineel.
Stel je voor dat je model een afbeelding classificeert als een “kat”. LIME zou kleine delen van de afbeelding (superpixels) uitschakelen of veranderen, en dan kijken hoe de voorspelling verandert. Als het uitschakelen van de snorharen en oren de kans op “kat” aanzienlijk verlaagt, concludeert LIME dat deze kenmerken belangrijk zijn voor die specifieke voorspelling.
KERNPUNT
LIME is uitstekend voor het begrijpen waarom een model een specifieke beslissing heeft genomen voor een individueel data instance. Het is model-agnostisch en flexibel, waardoor het breed toepasbaar is, zelfs op complexe modellen zoals diepe neurale netwerken.
CODE-UITLEG
Dit voorbeeld demonstreert hoe LIME kan worden gebruikt om de voorspelling van een individueel datapunkt uit te leggen voor een Random Forest Classifier. We maken een LIME explainer en genereren een verklaring voor een specifiek instance, waarbij de invloed van kenmerken op de voorspelde klasse wordt getoond.
# Vereist 'lime' installatie: pip install lime
import lime
import lime.lime_tabular
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import make_classification
# 1. Synthetische data genereren (hetzelfde als eerder)
X, y = make_classification(n_samples=1000, n_features=10, n_informative=5,
n_redundant=0, n_repeated=0, n_classes=2,
random_state=42)
feature_names = [f'feature_{i}' for i in range(X.shape[1])]
# 2. Random Forest model trainen
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X, y)
# 3. LIME Explainer initialiseren
# training_data: array van trainingsdata
# feature_names: lijst met namen van de kenmerken
# class_names: namen van de outputklassen (bijv. ['Geen Fraude', 'Fraude'])
# mode: 'classification' of 'regression'
explainer = lime.lime_tabular.LimeTabularExplainer(
training_data=X,
feature_names=feature_names,
class_names=['Klasse 0', 'Klasse 1'], # Voorbeeld klassenamen
mode='classification'
)
# 4. Een specifiek instance kiezen om uit te leggen (bijv. het 5e instance)
i = 4
exp = explainer.explain_instance(
data_row=X[i],
predict_fn=model.predict_proba,
num_features=5 # Hoeveel top kenmerken te tonen
)
print(f"Uitleg voor instance {i}, voorspelde klasse: {model.predict([X[i]])[0]}")
print("Belangrijkste kenmerken voor deze voorspelling:")
for feature, weight in exp.as_list():
print(f"- {feature}: {weight:.4f}")
# exp.show_in_notebook(show_all=False) # Visualisatie in Jupyter Notebook
Voordelen
✓ Model-agnostisch: werkt met elk black-box model.
✓ Lokale interpretaties: uitleg voor individuele voorspellingen.
✓ Relatief eenvoudig te visualiseren en te begrijpen.
Nadelen
✗ De definitie van “nabijheid” en de grootte van de perturbaties kunnen de resultaten beïnvloeden.
✗ Kan computationeel intensief zijn voor grote datasets of complexe modellen.
✗ “Instabiliteit”: kleine veranderingen in de input kunnen leiden tot significant verschillende verklaringen.
3. SHAP (SHapley Additive exPlanations)
SHAP is een van de meest geavanceerde en theoretisch onderbouwde XAI-technieken. Het is gebaseerd op de Shapley-waarden uit de coöperatieve speltheorie en wijst een eerlijke bijdrage toe aan elk kenmerk voor een voorspelling. SHAP-waarden vertegenwoordigen de gemiddelde marginale bijdrage van een kenmerk over alle mogelijke combinaties van kenmerken.
In tegenstelling tot LIME, dat een lokaal model traint, berekent SHAP de bijdrage van elk kenmerk aan de afwijking van de voorspelling van de baselinewaarde (de gemiddelde voorspelling). Dit maakt SHAP zowel lokaal als globaal interpreteerbaar en biedt een consistente manier om feature importance te kwantificeren, zelfs in de aanwezigheid van interacties tussen kenmerken.
KERNPUNT
SHAP-waarden bieden een robuuste en theoretisch onderbouwde methode voor het verklaren van modelvoorspellingen, zowel lokaal als globaal. Ze kwantificeren de impact van elk kenmerk op de afwijking van de baselinewaarde en zijn breed toepasbaar op diverse ML-modellen.
CODE-UITLEG
Dit Python-voorbeeld laat zien hoe SHAP-waarden kunnen worden berekend en gevisualiseerd voor een Random Forest Classifier. We gebruiken de shap bibliotheek om een explainer te creëren en een “force plot” te genereren, die de bijdrage van elk kenmerk aan een individuele voorspelling visualiseert.
# Vereist 'shap' installatie: pip install shap
import shap
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import make_classification
# 1. Synthetische data genereren
X, y = make_classification(n_samples=1000, n_features=10, n_informative=5,
n_redundant=0, n_repeated=0, n_classes=2,
random_state=42)
feature_names = [f'feature_{i}' for i in range(X.shape[1])]
X_df = pd.DataFrame(X, columns=feature_names)
# 2. Random Forest model trainen
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X, y)
# 3. SHAP Explainer initialiseren
# Voor tree-modellen is TreeExplainer efficiënt
explainer = shap.TreeExplainer(model)
# 4. SHAP-waarden berekenen voor de gehele dataset of een subset
shap_values = explainer.shap_values(X_df)
# 5. Visualiseer een individuele voorspelling (bijv. het 5e instance)
# shap_values[1] voor klasse 1 in een binaire classificatie
print(f"SHAP uitleg voor instance 4, voorspelde klasse: {model.predict([X_df.iloc[4]])[0]}")
# shap.initjs() # Initialiseer JavaScript voor interactieve plots (voor Jupyter)
# shap.force_plot(explainer.expected_value[1], shap_values[1][4,:], X_df.iloc[4]) # Visualisatie
# Als je geen Jupyter/interactieve omgeving hebt, kun je de waarden afdrukken:
print("SHAP-waarden voor de top 5 meest invloedrijke kenmerken:")
shap_df = pd.DataFrame({'feature': feature_names, 'shap_value': shap_values[1][4,:]})
shap_df['abs_shap_value'] = shap_df['shap_value'].abs()
shap_df = shap_df.sort_values(by='abs_shap_value', ascending=False)
print(shap_df.head(5))
# Globale SHAP-waarden (samenvattingsplot)
# shap.summary_plot(shap_values[1], X_df, plot_type="bar") # Globale feature importance
Voordelen
✓ Sterke theoretische fundering (Shapley-waarden).
✓ Biedt zowel lokale als globale interpretaties.
✓ Handelt interacties tussen kenmerken elegant af.
✓ Model-agnostisch (met verschillende explainers).
Nadelen
✗ Computationeel zeer intensief voor grote datasets en complexe modellen (hoewel TreeExplainer optimalisaties biedt).
✗ Kan complex zijn om te interpreteren zonder de juiste visualisaties.
PROBLEEMOPLOSSING
Uitdagingen en Oplossingen bij de Implementatie van XAI
Hoewel XAI krachtige tools biedt, brengt de implementatie ervan ook specifieke uitdagingen met zich mee. Developers moeten zich bewust zijn van deze knelpunten en proactief oplossingen overwegen om de effectiviteit van XAI te maximaliseren.
PROBLEEM 01
Computationele Kosten en Schaalbaarheid
Technieken zoals SHAP en LIME kunnen computationeel zeer intensief zijn, vooral bij grote datasets of complexe modellen (bijv. deep learning). Het genereren van verklaringen voor elke voorspelling in een productieomgeving kan onacceptabel hoge latentie veroorzaken.
OPLOSSING — Strategische Selectie en Sampling
Implementeer XAI-technieken strategisch. Overweeg sampling voor grootschalige analyse, waarbij verklaringen worden gegenereerd voor een representatieve subset van de data. Gebruik geoptimaliseerde SHAP-explainers zoals TreeExplainer voor boomgebaseerde modellen, die aanzienlijk sneller zijn. Voor deep learning modellen kunnen technieken zoals DeepExplainer of GradientExplainer worden gebruikt, maar vereisen vaak GPU-acceleratie. In sommige gevallen kan offline batch-processing van verklaringen een oplossing bieden voor online inferentie.
CODE-UITLEG
Dit codefragment toont hoe je SHAP-waarden voor een subset van de data kunt berekenen, wat de computationele belasting vermindert.
import shap
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import make_classification
X, y = make_classification(n_samples=10000, n_features=20, random_state=42)
feature_names = [f'feat_{i}' for i in range(X.shape[1])]
X_df = pd.DataFrame(X, columns=feature_names)
model = RandomForestClassifier(n_estimators=100, random_state=42).fit(X_df, y)
# Explainer initialiseren
explainer = shap.TreeExplainer(model)
# SHAP-waarden berekenen voor een representatieve steekproef van 1000 instances
sample_size = 1000
X_sample = X_df.sample(n=sample_size, random_state=42)
shap_values_sample = explainer.shap_values(X_sample)
print(f"SHAP-waarden berekend voor {sample_size} van de {len(X_df)} instances.")
# Verdere analyse met shap_values_sample
PROBLEEM 02
Complexiteit van Interpretatie voor Niet-Experts
De output van XAI-technieken kan zelf complex zijn. Een SHAP “force plot” of een LIME-verklaring vereist een zekere mate van technische kennis om correct te interpreteren. Dit kan een barrière vormen voor niet-technische stakeholders, zoals managers, ethische commissies of eindgebruikers.
OPLOSSING — Gebruiksvriendelijke Visualisaties en Narratieven
Creëer abstracte en geaggregeerde visualisaties die gemakkelijk te begrijpen zijn. Bijvoorbeeld, in plaats van ruwe SHAP-waarden, presenteer de top 5 meest invloedrijke factoren voor een beslissing met een eenvoudige uitleg in natuurlijke taal. Ontwikkel dashboards en rapporten die de belangrijkste XAI-inzichten samenvatten. Gebruik mensgerichte taal en storytelling om complexe concepten toegankelijk te maken. Tools zoals Dalex of Skater bieden vaak ingebouwde visualisaties die dit ondersteunen.
CODE-UITLEG
Een voorbeeld van hoe je een eenvoudige tekstuele uitleg van LIME-resultaten kunt genereren.
# Voortbouwend op het LIME-voorbeeld
# exp is het resultaat van explainer.explain_instance()
def format_lime_explanation(explanation_list, instance_id, predicted_class):
explanation_text = f"Voor data-instance {instance_id}, dat is voorspeld als '{predicted_class}', zijn de belangrijkste factoren:\n"
for feature, weight in explanation_list:
if weight > 0:
explanation_text += f"- '{feature}' verhoogt de kans op deze voorspelling met {weight*100:.2f}%\n"
else:
explanation_text += f"- '{feature}' verlaagt de kans op deze voorspelling met {abs(weight)*100:.2f}%\n"
return explanation_text
# Voorbeeld:
# i = 4
# predicted_class = model.predict([X[i]])[0]
# formatted_explanation = format_lime_explanation(exp.as_list(), i, f'Klasse {predicted_class}')
# print(formatted_explanation)
PROBLEEM 03
Verklaringen kunnen Misleidend zijn
XAI-technieken geven inzicht in hoe een model werkt, maar ze impliceren niet altijd causaliteit. Een kenmerk kan als “belangrijk” worden geïdentificeerd, maar dit betekent niet noodzakelijk dat het de oorzaak is van de voorspelling. Correlaties, vooroordelen in de data en de manier waarop het model is getraind, kunnen allemaal leiden tot misleidende interpretaties. Bijvoorbeeld, een model dat bepaalt of iemand in aanmerking komt voor een lening kan “postcode” als een belangrijk kenmerk identificeren. Dit kan duiden op een geografisch vooroordeel, zelfs als postcode zelf geen causale factor is.
OPLOSSING — Kritische Analyse en Domeinexpertise
Combineer XAI-resultaten altijd met diepgaande domeinexpertise. XAI-verklaringen moeten dienen als hypothesen die verder onderzoek en validatie vereisen, niet als definitieve waarheden. Voer gevoeligheidsanalyses uit, test op robuustheid en overweeg tegenfeitelijke verklaringen (wat als de input anders was geweest?). Betrek data scientists, ethici en domeinexperts in het interpretatieproces om context en kritische beoordeling toe te voegen. Dit helpt bij het identificeren van potentiële vooroordelen en het valideren van de logica van het model vanuit een menselijk perspectief.
KERNPUNT
De implementatie van XAI vereist zorgvuldige overweging van computationele kosten, de complexiteit van de interpretatie en de potentiële misleiding van verklaringen. Oplossingen omvatten strategische sampling, gebruiksvriendelijke visualisaties en een kritische analyse in combinatie met domeinexpertise.
PRAKTISCHE TOEPASSING
XAI Praktisch Toepassen in Jouw ML Workflow
Het integreren van XAI in een bestaande machine learning workflow hoeft niet overweldigend te zijn. Door XAI stapsgewijs toe te passen, kunnen developers de transparantie en betrouwbaarheid van hun modellen aanzienlijk verbeteren. Hier is een praktische handleiding voor het integreren van XAI in jouw ontwikkelingsproces in 2026.
Stap-voor-stap XAI Integratie
1
Begin met Baseline Interpretatie
Voordat je complexe XAI-technieken toepast, begin met eenvoudige methoden. Gebruik Feature Importance voor boomgebaseerde modellen of inspecteer coëfficiënten van lineaire modellen. Dit geeft een globaal beeld en helpt bij het valideren van je initiële aannames over de data en het modelgedrag. Documenteer deze bevindingen als je baseline.
2
Selecteer de Juiste XAI-Techniek
De keuze van de XAI-techniek hangt af van je model, de aard van de data en het soort verklaring dat je nodig hebt. Voor lokale, model-agnostische verklaringen is LIME vaak een goede start. Voor diepere, theoretisch onderbouwde inzichten, zowel lokaal als globaal, is SHAP superieur. Overweeg ook andere technieken zoals Permutation Importance of Partial Dependence Plots (PDPs) voor specifieke use-cases.
3
Integreer XAI in de Ontwikkelingscyclus
XAI moet geen eenmalige activiteit zijn, maar een integraal onderdeel van je ML-ontwikkelingscyclus. Gebruik XAI tijdens de modelselectie, hyperparameter-tuning en foutanalyse. Als je model onverwachte prestaties levert op de validatieset, gebruik dan XAI om te begrijpen waarom. Dit helpt bij het opsporen van datalekken, verkeerde aannames of modelvooroordelen vroeg in het proces.
4
Monitor XAI in Productie
XAI is ook cruciaal voor monitoring in productie. Modeldrift kan leiden tot onverwacht gedrag. Door XAI-verklaringen in de gaten te houden, kun je zien of de factoren die de modelbeslissingen beïnvloeden, verschuiven. Als een model plotseling begint te vertrouwen op andere kenmerken dan verwacht, kan dit duiden op een probleem met de data-input of een verandering in de onderliggende distributie, wat een her-training of aanpassing van het model rechtvaardigt. Tools voor MLOps zoals MLflow of Kubeflow beginnen steeds meer XAI-integraties te bieden voor continue monitoring.
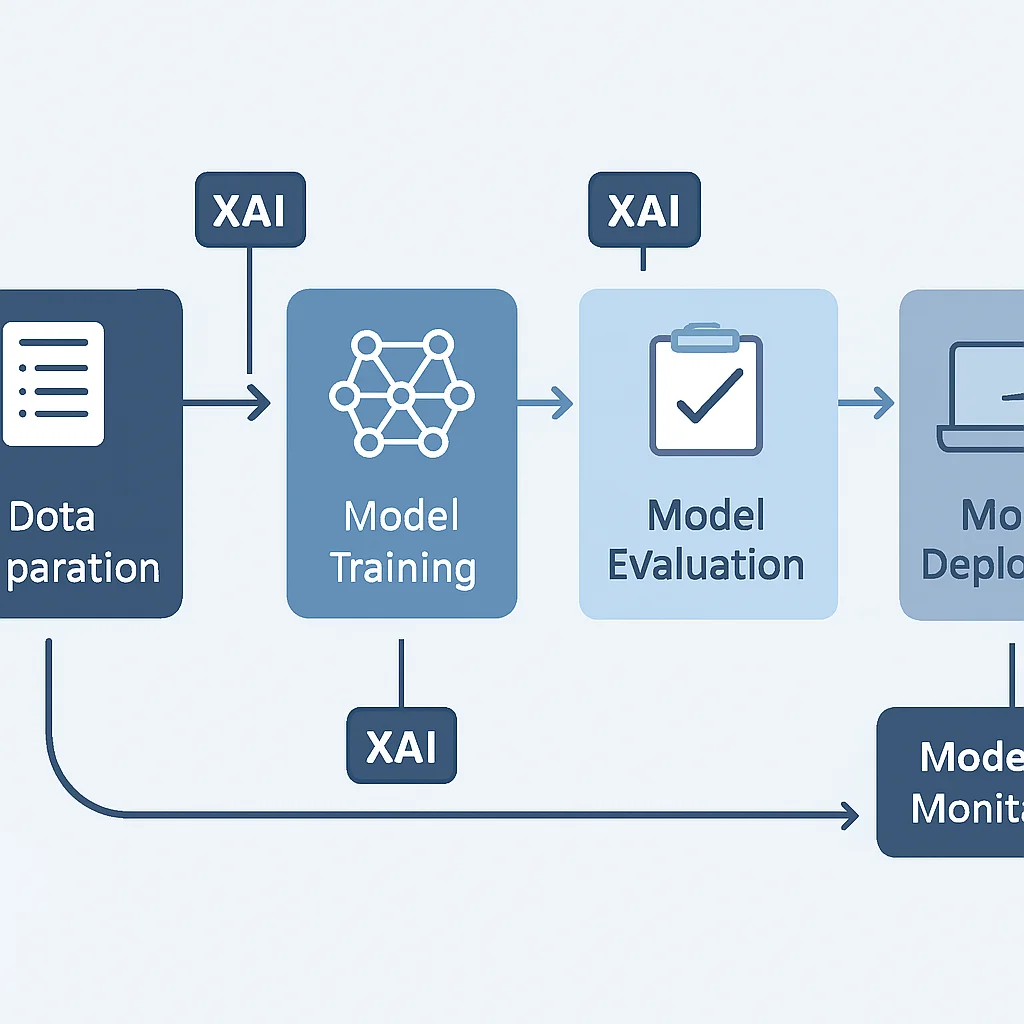
KERNPUNT
Integreer XAI in elke fase van de ML-workflow: van initiële baseline-interpretatie tot modelselectie, debugging en continue monitoring in productie. Kies de juiste technieken en visualiseer resultaten op een begrijpelijke manier om de acceptatie en effectiviteit van je AI-oplossingen te vergroten.
AFSLUITING
Conclusie en Toekomstperspectieven van XAI
Explainable AI is geëvolueerd van een academisch concept tot een onmisbare pijler in de ontwikkeling van verantwoorde en betrouwbare AI-systemen in 2026. Voor developers biedt XAI de tools om de black-box van complexe machine learning modellen te openen, waardoor dieper inzicht in modelgedrag, effectievere debugging en de mogelijkheid om ethische en regelgevende eisen na te leven, mogelijk wordt. Door technieken zoals Feature Importance, LIME en SHAP toe te passen, kunnen we de transparantie vergroten en het vertrouwen in AI-gestuurde beslissingen opbouwen.
De voordelen reiken verder dan alleen technische verbeteringen; ze omvatten ook een verhoogde acceptatie door gebruikers, verbeterde bedrijfsprocessen en de mogelijkheid om nieuwe, waardevolle inzichten uit data te halen die voorheen verborgen bleven. Het is niet langer voldoende om alleen nauwkeurige modellen te bouwen; we moeten ook kunnen uitleggen waarom ze nauwkeurig zijn en hoe ze tot hun conclusies komen.
De Toekomst van XAI
De ontwikkeling van XAI staat niet stil. We kunnen de volgende trends verwachten in de komende jaren:
1. Geautomatiseerde XAI: Meer geautomatiseerde tools en platforms die XAI-technieken naadloos integreren in MLOps-pijplijnen, waardoor het genereren en monitoren van verklaringen minder handmatige inspanning vereist.
2. Interactiviteit en Gebruikersgerichte Verklaringen: Ontwikkeling van meer interactieve XAI-interfaces die niet-technische gebruikers in staat stellen om “wat-als” scenario’s te verkennen en verklaringen te genereren die zijn afgestemd op hun specifieke behoeften en kennisniveau.
3. Causale XAI: Een groeiende focus op causale inferentie om niet alleen te verklaren welke kenmerken belangrijk zijn, maar ook waarom ze belangrijk zijn, en hoe veranderingen in input leiden tot veranderingen in output op een causaal niveau. Dit is cruciaal voor toepassingen in sectoren zoals medicijnontwikkeling en beleidsvorming.
4. XAI voor Multimodale AI: Naarmate AI-modellen complexer worden en meerdere datatypen (tekst, beeld, audio) verwerken, zullen er geavanceerdere XAI-technieken nodig zijn om deze multimodale beslissingen te verklaren.
KERNPUNT
XAI is fundamenteel voor de ontwikkeling van verantwoorde, betrouwbare en ethische AI-systemen. Developers die deze technieken beheersen, zullen niet alleen effectievere modellen bouwen, maar ook een cruciale rol spelen in de vormgeving van een toekomst waarin AI transparant en vertrouwenswaardig is.
Veelgestelde Vragen over Explainable AI (XAI)
Q. Wat is het belangrijkste verschil tussen LIME en SHAP?
A. LIME creëert lokale, interpreteerbare modellen rondom individuele datapunten om hun voorspellingen te verklaren, terwijl SHAP gebaseerd is op de Shapley-waarden uit de speltheorie om de eerlijke bijdrage van elk kenmerk aan een voorspelling toe te wijzen, zowel lokaal als globaal.
Q. Is XAI alleen relevant voor complexe deep learning modellen?
A. Nee, hoewel XAI cruciaal is voor het doorgronden van deep learning black-boxes, is het ook zeer relevant voor traditionele machine learning modellen zoals Random Forests of Gradient Boosting. Zelfs relatief eenvoudige modellen kunnen onverwacht gedrag vertonen dat baat heeft bij XAI-analyse voor debugging en validatie.
Q. Hoe helpt XAI bij het voldoen aan de AI Act in 2026?
A. De Europese AI Act vereist transparantie en interpreteerbaarheid, vooral voor hoogrisico AI-systemen. XAI-technieken stellen developers in staat om de beslissingen van hun modellen uit te leggen aan toezichthouders, potentiële vooroordelen te identificeren en de conformiteit met wettelijke eisen aan te tonen, wat essentieel is voor naleving in 2026.
Q. Kan XAI bias in mijn model volledig elimineren?
A. XAI kan bias in je model niet volledig elimineren, maar het is een krachtig hulpmiddel om het te detecteren en te kwantificeren. Door te begrijpen welke kenmerken bijdragen aan bevooroordeelde beslissingen, kunnen developers gerichte actie ondernemen om de data, het model of het trainingsproces aan te passen om de eerlijkheid te verbeteren.
Bedankt voor het lezen!
We hopen dat deze gids je heeft geholpen de waarde van Explainable AI voor je ontwikkelingspraktijk in 2026 te begrijpen. Door XAI te omarmen, bouw je niet alleen betere modellen, maar ook een fundament van vertrouwen en verantwoordelijkheid.
Vragen? Laat een reactie achter!