

SAMENVATTING
Realtime Monitoring met Prometheus en Grafana: Een Praktische Gids 2026
Leer hoe je Prometheus en Grafana configureert voor effectieve realtime monitoring van je cloud applicaties, inclusief dashboards en alerts voor optimale performance.
Keywords: Prometheus, Grafana, Cloud monitoring
ACHTERGROND
1. Achtergrond en Introductie tot Observability
In het dynamische landschap van softwareontwikkeling en IT-infrastructuur, vooral met de toenemende adoptie van cloud-native architecturen en microservices, is realtime monitoring niet langer een luxe, maar een absolute noodzaak. Bedrijven streven ernaar om in 2026 maximale beschikbaarheid, optimale prestaties en een snelle respons op incidenten te garanderen. Zonder effectieve monitoring vlieg je blind, wat kan leiden tot onopgemerkte problemen, downtime en uiteindelijk verlies van klanten en omzet.
De transitie naar de cloud brengt nieuwe uitdagingen met zich mee. Traditionele monitoringtools schieten vaak tekort in omgevingen waar infrastructuur vluchtig is, applicaties dynamisch schalen en services over meerdere, gedistribueerde componenten zijn verspreid. Dit vereist een moderne benadering van ‘observability’, die verder gaat dan alleen monitoring. Observability omvat het vermogen om de interne staat van een systeem af te leiden uit extern geproduceerde gegevens, zoals metrics, logs en traces. Het stelt teams in staat om niet alleen te zien wat er mis is, maar ook waarom.
Prometheus en Grafana zijn uitgegroeid tot de de facto standaard voor open-source monitoring in cloud-native omgevingen. Prometheus blinkt uit in het verzamelen van tijdreeksgegevens (metrics) met een krachtige querytaal (PromQL) en een flexibel alerting-systeem. Grafana vult dit aan door deze gegevens om te zetten in intuïtieve en interactieve dashboards, waardoor complexe datasets toegankelijk worden voor iedereen, van engineers tot management. Samen vormen ze een robuust en schaalbaar platform dat organisaties helpt om proactief te handelen en de gezondheid van hun systemen te waarborgen.
KERNPUNT
Realtime monitoring met Prometheus en Grafana is essentieel in 2026 voor cloud-native omgevingen. Het stelt organisaties in staat om proactief problemen te detecteren, te analyseren en op te lossen, wat cruciaal is voor bedrijfscontinuïteit en klanttevredenheid.
De synergie tussen Prometheus en Grafana is ongeëvenaard. Prometheus’ pull-model voor metrische verzameling, gekoppeld aan zijn service discovery mogelijkheden, maakt het ideaal voor dynamische infrastructuren zoals Kubernetes. Grafana’s flexibiliteit in databronnen en visualisatietypen zorgt ervoor dat elke metric, van CPU-gebruik tot applicatie-specifieke business-KPI’s, op een zinvolle manier kan worden gepresenteerd. Dit maakt het niet alleen een technisch hulpmiddel, maar ook een strategisch instrument voor datagedreven besluitvorming.
KERNINHOUD
2. Prometheus: Architectuur, Installatie en Configuratie
Prometheus is een krachtig monitoring- en alerting-toolkit dat oorspronkelijk is ontwikkeld bij SoundCloud. Het kernconcept is gebaseerd op een pull-model, waarbij de Prometheus-server periodiek metrics ‘scrapt’ van geconfigureerde endpoints. Deze endpoints worden meestal blootgesteld door ‘exporters’ of direct door geinstrumenteerde applicaties. Laten we de architectuur en de basisconfiguratie nader bekijken.
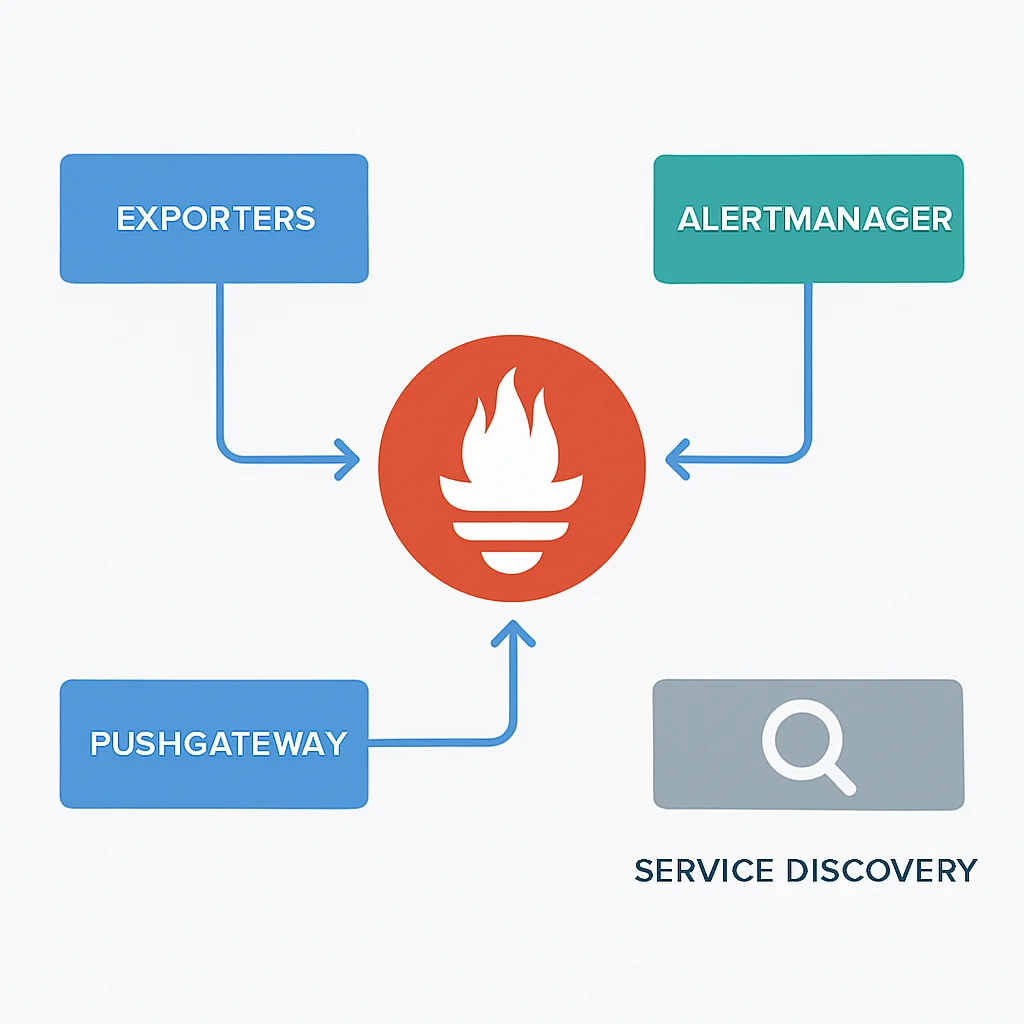
Prometheus Architectuur Componenten
De Prometheus-architectuur bestaat uit verschillende componenten die naadloos samenwerken:
Prometheus Server: Dit is de kerncomponent die metrics scrapt en opslaat in een tijdreeksdatabase (TSDB). Het verwerkt ook PromQL-queries en genereert alerts.
Exporters: Dit zijn kleine applicaties die metrics van bestaande systemen (bijv. databases, servers, berichtensystemen) omzetten naar het Prometheus-formaat. Voorbeelden zijn de Node Exporter (voor OS-metrics), cAdvisor (voor container-metrics) en MySQL Exporter.
Pushgateway: Voor kortstondige of batch-taken die niet lang genoeg leven om gescraped te worden, kan de Pushgateway worden gebruikt. Applicaties pushen hun metrics naar de Pushgateway, die deze vervolgens beschikbaar stelt voor Prometheus om te scrapen.
Alertmanager: Ontvangt alerts van de Prometheus-server, groepeert ze, elimineert duplicaten en stuurt ze naar de juiste ontvangers (e-mail, Slack, PagerDuty, etc.).
Service Discovery: Prometheus kan dynamisch scrape-targets ontdekken in complexe omgevingen zoals Kubernetes, AWS EC2, of Consul, wat handmatig beheer overbodig maakt.
Installatie van Prometheus
De eenvoudigste manier om Prometheus te installeren is door de binaire bestanden te downloaden van de officiële website. Voor Linux-systemen kun je de volgende stappen volgen:
CODE-UITLEG
Deze code downloadt, extraheert en verplaatst de Prometheus binaire bestanden en configuratiebestanden naar de juiste locaties op een Linux-systeem. Het creëert ook een systeemgebruiker en -groep voor Prometheus.
# Download Prometheus
wget https://github.com/prometheus/prometheus/releases/download/v2.50.1/prometheus-2.50.1.linux-amd64.tar.gz
# Extract
tar xvfz prometheus-2.50.1.linux-amd64.tar.gz
cd prometheus-2.50.1.linux-amd64/
# Create necessary directories
sudo mkdir -p /etc/prometheus /var/lib/prometheus
# Create user and group
sudo groupadd --system prometheus
sudo useradd -s /sbin/nologin --system -g prometheus prometheus
# Copy binaries
sudo cp prometheus /usr/local/bin/
sudo cp promtool /usr/local/bin/
# Copy configuration files and set ownership
sudo cp prometheus.yml /etc/prometheus/
sudo cp consoles/ /etc/prometheus
sudo cp console_libraries/ /etc/prometheus
sudo chown -R prometheus:prometheus /etc/prometheus /var/lib/prometheus
sudo chown prometheus:prometheus /usr/local/bin/prometheus /usr/local/bin/promtool
# Create systemd service file (e.g., /etc/systemd/system/prometheus.service)
# [Unit]
# Description=Prometheus
# Documentation=https://prometheus.io/docs/
# Wants=network-online.target
# After=network-online.target
#
# [Service]
# User=prometheus
# Group=prometheus
# Restart=on-failure
# ExecStart=/usr/local/bin/prometheus \
# --config.file /etc/prometheus/prometheus.yml \
# --storage.tsdb.path /var/lib/prometheus \
# --web.console.templates=/etc/prometheus/consoles \
# --web.console.libraries=/etc/prometheus/console_libraries \
# --web.listen-address="0.0.0.0:9090"
#
# [Install]
# WantedBy=multi-user.target
# Reload systemd and start Prometheus
sudo systemctl daemon-reload
sudo systemctl start prometheus
sudo systemctl enable prometheusConfiguratie van Prometheus (prometheus.yml)
Het hart van Prometheus is het configuratiebestand prometheus.yml. Hierin definieer je globaal scrape-intervallen, alerting-regels en vooral de scrape-targets. Een basisconfiguratie ziet er als volgt uit:
CODE-UITLEG
Dit is een voorbeeld van een Prometheus-configuratiebestand. Het definieert een globaal scrape-interval en een ‘job’ genaamd prometheus die de Prometheus-server zelf monitort, en een ‘job’ voor de node_exporter.
global:
scrape_interval: 15s # Hoe vaak Prometheus metrics scrapt
scrape_configs:
- job_name: 'prometheus'
# Monitort de Prometheus-server zelf
static_configs:
- targets: ['localhost:9090']
- job_name: 'node_exporter'
# Monitort een server met de Node Exporter
static_configs:
- targets: ['your_server_ip:9100'] # Vervang door het IP-adres van je server
labels:
env: production
datacenter: eu-west-1
- job_name: 'my_application'
# Monitort een custom applicatie die metrics blootstelt op /metrics
static_configs:
- targets: ['my_app_ip:8080']
labels:
app: webapp
version: v1.0Na het wijzigen van prometheus.yml, moet je Prometheus opnieuw laden of herstarten om de wijzigingen toe te passen. Een snelle manier om de configuratie te controleren is met promtool check config prometheus.yml.
KERNPUNT
De prometheus.yml is cruciaal voor het definiëren van welke targets Prometheus moet scrapen en hoe frequent. Effectief gebruik van job_name en labels is essentieel voor een georganiseerde monitoringomgeving.
Voor Kubernetes-omgevingen wordt Service Discovery vaak geconfigureerd met behulp van de Kubernetes API, waardoor Prometheus automatisch nieuwe pods en services kan ontdekken zonder handmatige configuratie. Dit is een gamechanger voor de schaalbaarheid en onderhoudbaarheid van monitoring in dynamische cloud-native setups, en een reden waarom Prometheus zo populair is in 2026.
KERNINHOUD
3. Grafana: Visualisatie en Dashboards voor Inzicht
Waar Prometheus de data verzamelt en opslaat, is Grafana de bril die we opzetten om die data te begrijpen. Grafana is een open-source platform voor datavisualisatie en -analyse, waarmee je interactieve dashboards kunt creëren vanuit diverse databronnen, waaronder Prometheus. Het biedt een rijke set aan visualisatiemogelijkheden, van lijngrafieken en staafdiagrammen tot heatmaps en tabellen, waardoor je complexe metrieken kunt omzetten in bruikbare inzichten.
Installatie van Grafana
Grafana kan op verschillende manieren worden geïnstalleerd: als stand-alone applicatie, via Docker, of als een Kubernetes-deployment. Voor een snelle installatie op een Debian/Ubuntu-systeem:
CODE-UITLEG
Deze commando’s voegen de Grafana APT-repository toe aan je systeem, installeren Grafana en configureren het om bij het opstarten te starten.
# Update package list
sudo apt-get update
# Install dependencies
sudo apt-get install -y apt-transport-https software-properties-common wget
# Import GPG key
wget -q -O - https://packages.grafana.com/gpg.key | sudo apt-key add -
# Add Grafana stable repository
echo "deb https://packages.grafana.com/oss/deb stable main" | sudo tee -a /etc/apt/sources.list.d/grafana.list
# Update and install Grafana
sudo apt-get update
sudo apt-get install grafana
# Start Grafana server and enable it on boot
sudo systemctl daemon-reload
sudo systemctl start grafana-server
sudo systemctl enable grafana-serverNa installatie is Grafana toegankelijk via poort 3000 (standaard). De standaard inloggegevens zijn admin / admin, die je direct na de eerste login moet wijzigen.
Prometheus als Databron Toevoegen
De eerste stap is het configureren van Prometheus als databron in Grafana. Ga in Grafana naar Configuration > Data sources > Add data source en selecteer ‘Prometheus’. Voer de URL van je Prometheus-server in (bijv. http://localhost:9090 of de juiste IP/hostname), en klik op ‘Save & Test’.
Effectieve Dashboards Bouwen
Het bouwen van een effectief dashboard begint met het identificeren van de belangrijkste metrics. Voor infrastructuur monitoring zijn dit vaak CPU-gebruik, geheugengebruik, schijfruimte en netwerk-I/O. Voor applicaties zijn request rates, error rates, latency en concurrency van belang. Grafana biedt een breed scala aan panel-typen:
Graph: Voor tijdreeksdata, ideaal voor trends en historische analyse.
Stat: Toont een enkele statistische waarde, vaak met kleurcodering voor drempelwaarden.
Gauge: Visualiseert een enkele waarde op een schaal, nuttig voor capaciteitsmonitoring.
Table: Voor het presenteren van meerdere metrics of labelcombinaties in tabelvorm.
Heatmap: Ideaal voor het visualiseren van distributies van latency of andere waarden over tijd.

Bij het maken van een nieuw panel selecteer je Prometheus als databron en voer je PromQL-queries in om de gewenste metrics op te halen. Hier zijn enkele voorbeelden van PromQL-queries:
CODE-UITLEG
Deze PromQL-queries illustreren hoe je CPU-gebruik, geheugenverbruik en HTTP-request rates kunt opvragen en aggregeren voor visualisatie in Grafana.
# CPU Usage (percentage) over the last 5 minutes, by instance
100 - avg by (instance) (rate(node_cpu_seconds_total{mode="idle"}[5m])) * 100
# Memory Usage (bytes) by instance
node_memory_MemTotal_bytes - node_memory_MemFree_bytes - node_memory_Buffers_bytes - node_memory_Cached_bytes
# HTTP Request Rate (requests per second) for a specific application
sum by (job, instance) (rate(http_requests_total{job="my_application"}[1m]))Gebruik van variabelen in Grafana-dashboards is een krachtige functie. Dit stelt gebruikers in staat om dynamisch te filteren op labels zoals instance, job of app, waardoor één dashboard bruikbaar wordt voor meerdere servers of applicaties. Dit verhoogt de efficiëntie aanzienlijk, vooral in grote, gedistribueerde systemen.
KERNPUNT
Grafana transformeert ruwe Prometheus-metrics in visueel aantrekkelijke en functionele dashboards. Het effectief gebruiken van PromQL-queries en Grafana-variabelen is essentieel voor het creëren van dashboards die snel inzicht bieden in de systeemstatus en prestaties.
De Grafana Community biedt duizenden kant-en-klare dashboards die je kunt importeren en aanpassen. Dit versnelt de setup aanzienlijk, vooral voor veelvoorkomende monitoringbehoeften zoals Kubernetes, Node Exporter of Nginx. In 2026 is de beschikbaarheid van deze community-resources een enorme troef voor snelle implementatie.
PROBLEEMOPLOSSING
4. Alerting en Incidentmanagement met Alertmanager
Monitoring is pas echt effectief als het je waarschuwt wanneer er actie nodig is. Prometheus’ Alertmanager is de centrale hub voor het verwerken van alerts die door de Prometheus-server worden gegenereerd. Het is ontworpen om alert-ruis te verminderen en ervoor te zorgen dat de juiste persoon op het juiste moment op de hoogte wordt gebracht van kritieke problemen.
Alerting Regels in Prometheus
Alerts worden gedefinieerd in aparte YAML-bestanden die door Prometheus worden geladen. Deze bestanden bevatten regels op basis van PromQL-queries die bepalen wanneer een alert moet worden geactiveerd. Een typische alertregel heeft een naam, een expressie (PromQL-query), een duur (FOR) en annotaties (beschrijvingen, runbooks). Hier is een voorbeeld van een alert-regel:
CODE-UITLEG
Dit YAML-bestand definieert twee alert-regels: één voor hoog CPU-gebruik en één voor bijna volle schijfruimte. De alerts worden geactiveerd als de conditie gedurende 5 minuten aanhoudt.
# alerts.yml
groups:
- name: general.rules
rules:
- alert: HighCpuUsage
expr: 100 - (avg by (instance) (rate(node_cpu_seconds_total{mode="idle"}[5m])) * 100) > 80
for: 5m
labels:
severity: critical
annotations:
summary: "Hoge CPU-gebruik op {{ $labels.instance }}"
description: "CPU-gebruik op {{ $labels.instance }} is hoger dan 80% voor 5 minuten."
- alert: DiskNearlyFull
expr: node_filesystem_avail_bytes{fstype="ext4",mountpoint="/"} / node_filesystem_size_bytes{fstype="ext4",mountpoint="/"} * 100 < 10
for: 5m
labels:
severity: warning
annotations:
summary: "Schijfruimte bijna vol op {{ $labels.instance }}"
description: "Minder dan 10% schijfruimte beschikbaar op {{ $labels.instance }} (mountpoint: /)."Om deze regels te laden, voeg je ze toe aan je prometheus.yml:
CODE-UITLEG
Deze configuratie-snippet vertelt Prometheus waar de alert-regels en de Alertmanager-service te vinden zijn.
# In prometheus.yml
rule_files:
- "/etc/prometheus/alerts.yml" # Pad naar je alert regels
alerting:
alertmanagers:
- static_configs:
- targets: ['localhost:9093'] # Adres van je AlertmanagerConfiguratie van Alertmanager
De Alertmanager configureer je via het bestand alertmanager.yml. Hierin definieer je hoe alerts moeten worden gerouteerd, gegroepeerd en naar welke ontvangers ze moeten worden gestuurd. Belangrijke concepten zijn receivers (e-mail, Slack, PagerDuty), routes (voorwaardelijke routering van alerts) en group_by (om vergelijkbare alerts te bundelen).
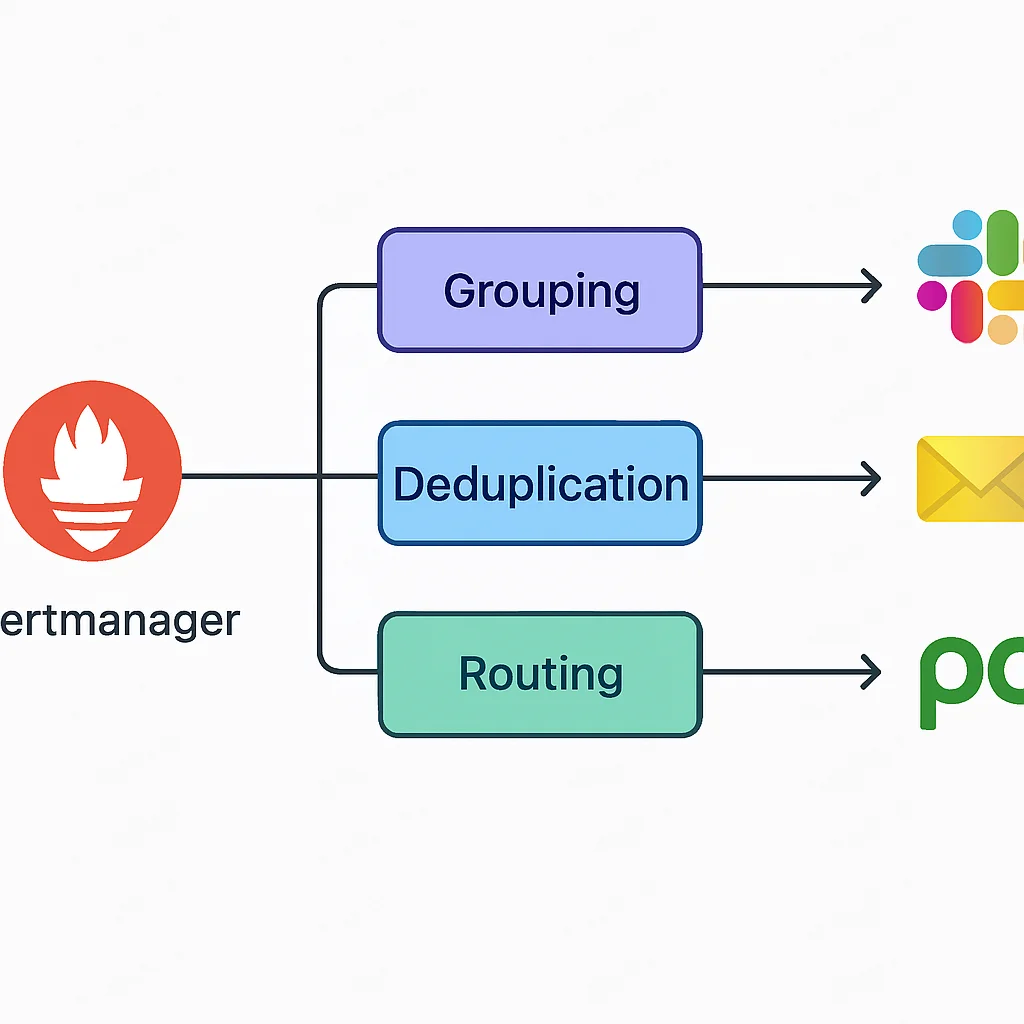
CODE-UITLEG
Dit is een voorbeeld van een Alertmanager-configuratie. Het definieert een Slack-ontvanger en een standaardroute die alle alerts naar Slack stuurt, gegroepeerd per alertnaam en instantie.
# alertmanager.yml
global:
resolve_timeout: 5m
route:
group_by: ['alertname', 'instance']
group_wait: 30s
group_interval: 5m
repeat_interval: 1h
receiver: 'slack-notifications' # Standaard ontvanger
routes:
- match:
severity: 'critical'
receiver: 'slack-notifications'
continue: true # Ga verder met andere routes
- match:
severity: 'warning'
receiver: 'slack-notifications'
receivers:
- name: 'slack-notifications'
slack_configs:
- channel: '#alerts' # Je Slack-kanaal
api_url: 'https://hooks.slack.com/services/T00000000/B00000000/XXXXXXXXXXXXXXXXXXXXXXXX' # Je Slack Webhook URL
send_resolved: true
title: '[{{ .Status | toUpper }}] {{ .CommonLabels.alertname }}'
text: '{{ .CommonAnnotations.description }}\nLabels: {{ .CommonLabels }}'KERNPUNT
Alertmanager is essentieel voor het stroomlijnen van incidentmanagement. Door alerts te groeperen en te routeren naar de juiste kanalen, minimaliseer je alert-ruis en zorg je voor een snelle respons op kritieke gebeurtenissen.
Een veelvoorkomend probleem is ‘alert fatigue’, waarbij teams overspoeld worden met te veel alerts, waardoor echte problemen over het hoofd worden gezien. Best practices voor 2026 omvatten het zorgvuldig definiëren van alertdrempels, het gebruik van FOR-clausules om flapperende alerts te voorkomen, en het implementeren van slimme groeperingsstrategieën in Alertmanager. Het is ook cruciaal om alerts te koppelen aan duidelijke runbooks voor snelle probleemoplossing.
PRAKTISCHE TOEPASSING
5. Praktische Implementatie: Monitoring van een Cloud Microservice
Laten we de theorie in de praktijk brengen door een scenario te bekijken waarin we een eenvoudige microservice, draaiend op een cloud-gebaseerde VM of in een Kubernetes-cluster, monitoren met Prometheus en Grafana. Dit voorbeeld toont de end-to-end flow van metric-verzameling tot visualisatie en alerting.
Scenario: Monitoring van een ‘Order Processing’ Microservice
Stel, we hebben een Python Flask microservice genaamd order-api die bestellingen verwerkt. We willen de volgende aspecten monitoren:
1. Infrastructuur Metrics: CPU, geheugen, schijfruimte van de host-VM of Kubernetes-node.
2. Applicatie Metrics: Aantal verwerkte orders, foutpercentage, latency van API-calls.
3. Alerting: Waarschuwen bij hoog foutpercentage of als de service niet meer reageert.
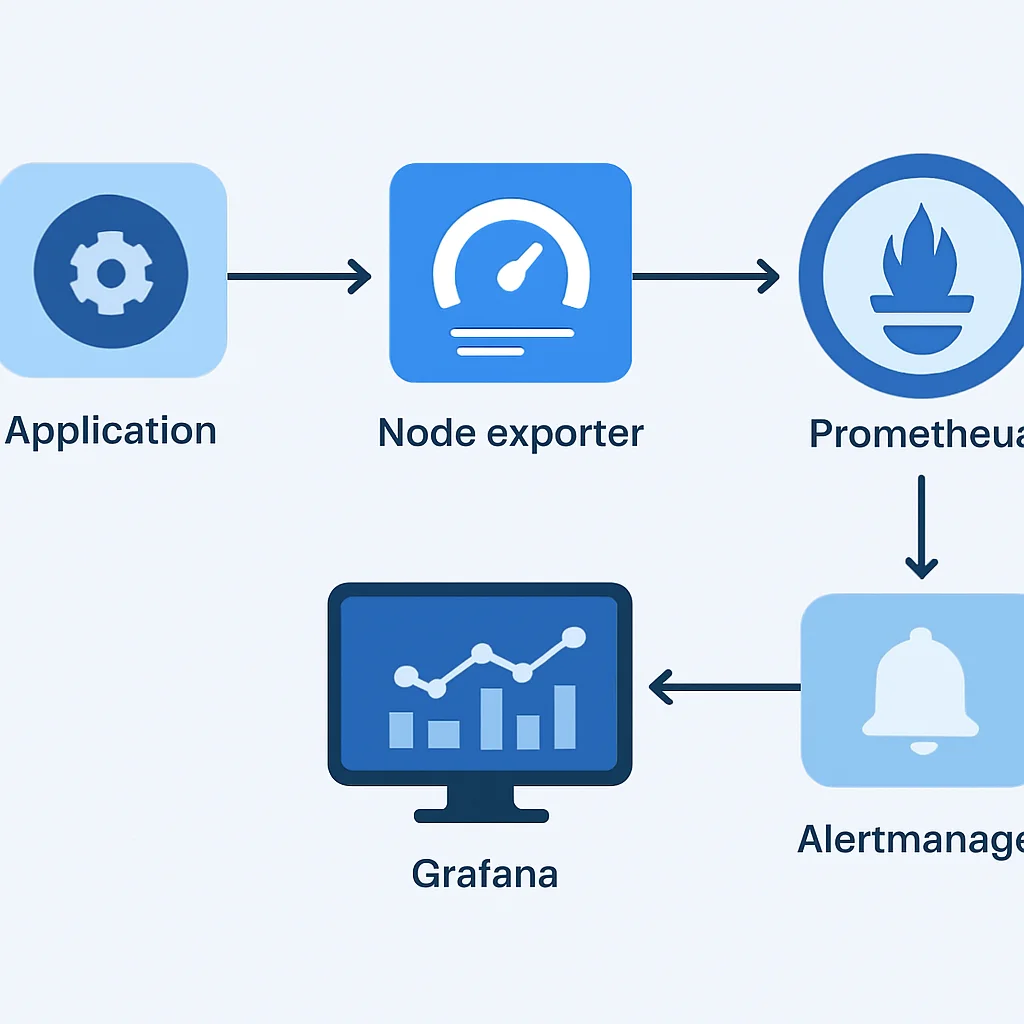
Stap 1: Instrumentatie van de Applicatie
We gebruiken de Prometheus Python client library om custom metrics bloot te stellen via een /metrics endpoint. Dit endpoint wordt vervolgens gescraped door Prometheus.
CODE-UITLEG
Dit Python Flask-voorbeeld initialiseert Prometheus metrics voor orderverwerking, zoals een teller voor het aantal orders en een histogram voor de verwerkingstijd. Het /metrics endpoint exposeert deze metrics.
# app.py (vereist 'pip install prometheus_client Flask')
from flask import Flask, request
from prometheus_client import start_http_server, Counter, Histogram
import time
import random
app = Flask(__name__)
# Prometheus metrics
REQUEST_COUNT = Counter('http_requests_total', 'Total HTTP Requests', ['method', 'endpoint', 'status'])
REQUEST_LATENCY = Histogram('http_request_duration_seconds', 'HTTP Request Latency', ['method', 'endpoint'])
ORDER_PROCESSED_COUNT = Counter('orders_processed_total', 'Total orders processed', ['status'])
@app.route('/order', methods=['POST'])
def process_order():
start_time = time.time()
method = request.method
endpoint = request.path
status = 'success'
try:
# Simulate order processing
if random.random() < 0.1: # 10% kans op fout
raise Exception("Failed to process order")
time.sleep(random.uniform(0.05, 0.5)) # Simulate work
ORDER_PROCESSED_COUNT.labels(status='success').inc()
return {"message": "Order processed successfully"}, 200
except Exception as e:
status = 'error'
ORDER_PROCESSED_COUNT.labels(status='error').inc()
return {"error": str(e)}, 500
finally:
REQUEST_LATENCY.labels(method=method, endpoint=endpoint).observe(time.time() - start_time)
REQUEST_COUNT.labels(method=method, endpoint=endpoint, status=status).inc()
@app.route('/health')
def health_check():
return {"status": "UP"}, 200
if __name__ == '__main__':
# Start up the server to expose the metrics.
start_http_server(8000) # Metrics exposed on port 8000
app.run(host='0.0.0.0', port=5000) # Flask app on port 5000De metrics zijn nu beschikbaar op http://<app_ip>:8000/metrics.
Stap 2: Node Exporter Implementeren
Om infrastructuur metrics te verzamelen, installeren we de Node Exporter op de VM of als een DaemonSet in Kubernetes die op elke node draait. De Node Exporter exposeert metrics op poort 9100.
KERNPUNT
Instrumentatie van applicaties met Prometheus client libraries en het gebruik van generieke exporters (zoals Node Exporter) zijn de fundamenten voor een complete monitoringstrategie, waardoor zowel applicatie-specifieke als infrastructuur-metrics worden vastgelegd.
Stap 3: Prometheus Configuratie voor Scrape Targets
We voegen nieuwe scrape-jobs toe aan prometheus.yml:
CODE-UITLEG
Deze Prometheus-configuratie voegt twee nieuwe scrape-targets toe: de node_exporter op poort 9100 en de order-api op poort 8000.
# prometheus.yml (aanvulling)
scrape_configs:
- job_name: 'node_exporter'
static_configs:
- targets: ['<IP_of_VM>:9100']
labels:
env: production
service: order-processing
- job_name: 'order-api'
static_configs:
- targets: ['<IP_of_VM>:8000'] # Poort waar de Python app metrics exposeert
labels:
env: production
service: order-api
component: backendHerstart Prometheus na deze wijzigingen.
Stap 4: Grafana Dashboards en Alerts
In Grafana maken we een nieuw dashboard met panelen voor:
CPU/Geheugen Gebruik: Gebruik PromQL-queries zoals 100 - avg by (instance) (rate(node_cpu_seconds_total{mode="idle"}[5m])) * 100.
Orders per Seconde: sum(rate(orders_processed_total{status="success", job="order-api"}[1m])).
Foutpercentage: sum(rate(orders_processed_total{status="error", job="order-api"}[1m])) / sum(rate(orders_processed_total{job="order-api"}[1m])) * 100.
We voegen ook alert-regels toe aan alerts.yml:
CODE-UITLEG
Deze alert-regels waarschuwen als het foutpercentage van de order-api hoger is dan 5% gedurende 2 minuten, of als de service langer dan 1 minuut onbereikbaar is.
# alerts.yml (aanvulling)
groups:
- name: order-api.rules
rules:
- alert: OrderApiHighErrorRate
expr: (sum(rate(orders_processed_total{status="error", job="order-api"}[2m])) / sum(rate(orders_processed_total{job="order-api"}[2m]))) * 100 > 5
for: 2m
labels:
severity: critical
service: order-api
annotations:
summary: "Hoge foutenpercentage op Order API"
description: "De Order API rapporteert een foutpercentage van meer dan 5% voor 2 minuten."
- alert: OrderApiDown
expr: up{job="order-api"} == 0
for: 1m
labels:
severity: critical
service: order-api
annotations:
summary: "Order API is down"
description: "De Order API is niet bereikbaar voor scraping gedurende 1 minuut."Door deze stappen te volgen, beschikken we over een complete monitoringoplossing voor onze order-api, inclusief infrastructuur, applicatie metrics, visualisatie en alerting. Dit stelt het team in staat om proactief problemen te identificeren en op te lossen, wat essentieel is voor de betrouwbaarheid van de service in 2026.
Use Case: E-commerce Platform Prestatiebewaking
Een groot e-commerce platform gebruikt Prometheus en Grafana om de prestaties van hun microservices-architectuur te monitoren. Ze hebben dashboards gecreëerd die key metrics zoals transacties per seconde, winkelwagen conversieratio’s en responstijden van de betaalgateway visualiseren. Alertmanager is geconfigureerd om het SRE-team onmiddellijk te waarschuwen via PagerDuty als het foutpercentage van de checkout-service boven de 1% komt of als de gemiddelde latency van de productcatalogus-API de 500ms overschrijdt. Dit stelt hen in staat om tijdens piekuren, zoals Black Friday, proactief in te grijpen en potentiële omzetverliezen te voorkomen, wat resulteerde in een reductie van downtime met 30% in het afgelopen jaar.
AFSLUITING
6. Best Practices en Toekomstige Trends in 2026
Nu we de technische implementatie van Prometheus en Grafana hebben behandeld, is het belangrijk om te kijken naar best practices voor schaalbaarheid, veiligheid en de bredere context van observability. Het landschap van monitoring evolueert snel, en in 2026 zien we een aantal duidelijke trends.
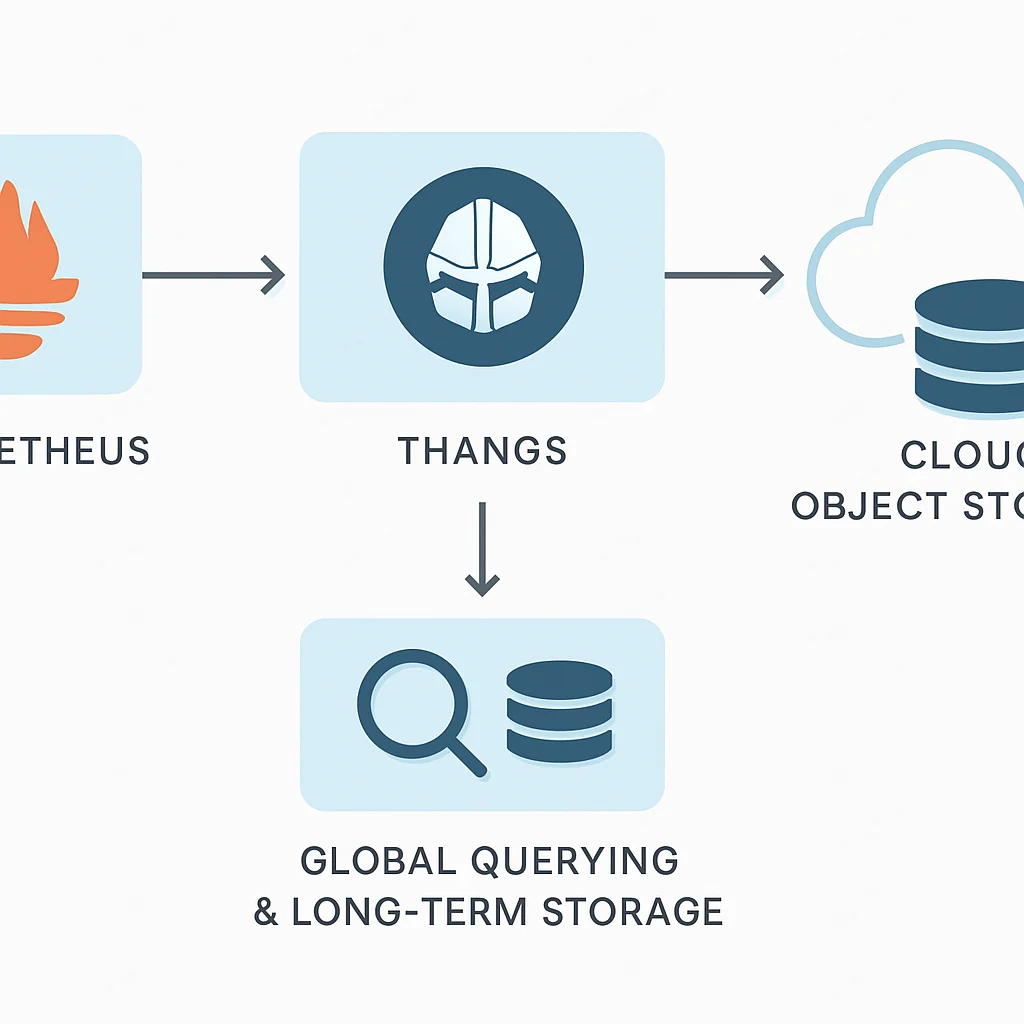
Schaalbaarheid en Langetermijnopslag
Prometheus is van nature ontworpen voor schaalbaarheid binnen één datacenter of Kubernetes-cluster. Voor langetermijnopslag van metrics over meerdere clusters of regio’s zijn projecten zoals Thanos en Cortex onmisbaar. Deze oplossingen bieden:
Thanos: Biedt globale query-mogelijkheden over meerdere Prometheus-instanties, downsampling voor langetermijnopslag in object storage (S3, GCS) en hoge beschikbaarheid.
Cortex: Een geclusterd, multi-tenant, schaalbaar Prometheus-compatibel systeem dat langetermijnopslag en schaalbaarheid biedt als een service.
In 2026 is de integratie met dergelijke oplossingen een standaardpraktijk voor grote organisaties die een uniforme blik op hun gedistribueerde systemen nodig hebben, met retentieperioden van maanden tot jaren.
Observability: Metrics, Logs en Traces
Hoewel Prometheus en Grafana uitblinken in metrics, is een complete observability-strategie pas compleet met logs en traces. De ‘drie pijlers van observability’ werken samen om een diepgaand begrip van de systeemstatus te bieden:
Metrics (Prometheus): Numerieke waarden over tijd, ideaal voor het detecteren van trends en afwijkingen.
Logs (Loki, ELK Stack): Gedetailleerde, contextuele gebeurtenissen, cruciaal voor debugging en root cause analysis.
Traces (Tempo, Jaeger): End-to-end weergave van verzoeken door gedistribueerde systemen, essentieel voor het identificeren van knelpunten in microservices-architecturen.
Grafana Labs biedt een geïntegreerde stack met Loki (voor logs) en Tempo (voor traces) die naadloos samenwerken met Prometheus en Grafana, waardoor een ‘single pane of glass’ voor alle observability-data ontstaat. Dit is een belangrijke trend in 2026 voor het vereenvoudigen van complexe diagnoseprocessen.
Beveiligingsoverwegingen
Bij het implementeren van monitoringoplossingen is beveiliging van cruciaal belang. Enkele belangrijke punten:
Netwerkisolatie: Plaats Prometheus en zijn exporters in een geïsoleerd netwerksegment, bij voorkeur achter een firewall.
Toegangscontrole: Beperk de toegang tot de web-interfaces van Prometheus, Alertmanager en Grafana. Gebruik sterke authenticatie en autorisatie (bijv. OAuth, LDAP, SAML voor Grafana).
TLS/SSL: Versleutel alle communicatie tussen componenten (Prometheus naar exporters, Prometheus naar Alertmanager, Grafana naar databronnen) met TLS/SSL.
Minimale privileges: Draai Prometheus en exporters met minimale benodigde privileges op het besturingssysteem.
KERNPUNT
Een holistische observability-strategie omvat niet alleen metrics, maar ook logs en traces, geïntegreerd in één platform. Schaalbaarheid via oplossingen zoals Thanos en Cortex, gecombineerd met robuuste beveiligingsmaatregelen, zijn essentieel voor moderne cloud-native omgevingen in 2026.
De ontwikkelingen in de observability-ruimte gaan snel. Met de opkomst van AI-gedreven analyse en AIOps-platforms zullen monitoringtools in 2026 steeds intelligenter worden in het detecteren van anomalieën en het voorspellen van problemen, waardoor de rol van de mens verschuift van reactief naar proactief en strategisch. Het beheersen van de basis met Prometheus en Grafana legt een solide fundament voor deze toekomstige innovaties.
Voordelen van Prometheus & Grafana
✓ Open Source: Geen licentiekosten, grote community-ondersteuning.
✓ Cloud-Native Design: Ideaal voor Kubernetes en microservices.
✓ Krachtige Querytaal (PromQL): Flexibele data-analyse en aggregatie.
✓ Rijke Visualisatie (Grafana): Intuïtieve en aanpasbare dashboards.
✓ Robuust Alerting: Geavanceerd incidentmanagement met Alertmanager.
Nadelen van Prometheus & Grafana
✗ Langetermijnopslag: Vereist aanvullende oplossingen (Thanos/Cortex) voor schaalbaarheid over langere perioden.
✗ Leercurve: PromQL en de configuratie van Alertmanager kunnen complex zijn voor beginners.
✗ Geen Logs/Traces OOB: Vereist integratie met andere tools (Loki/Tempo/Jaeger) voor complete observability.
✗ Resource-intensief: Kan aanzienlijke CPU- en schijfresources verbruiken bij grote schaal.
Veelgestelde Vragen (FAQ)
Q. Wat is het belangrijkste verschil tussen Prometheus en Grafana?
Prometheus is een monitoringtoolkit die verantwoordelijk is voor het verzamelen en opslaan van tijdreeksmetrics en het genereren van alerts. Grafana is daarentegen een datavisualisatieplatform dat deze metrics van Prometheus (en andere bronnen) gebruikt om interactieve dashboards te creëren voor analyse en inzicht.
Q. Hoe schaal ik Prometheus voor grote omgevingen in 2026?
Voor grote schaalbaarheid en langetermijnopslag van metrics, vooral over meerdere clusters of regio’s, kun je Prometheus integreren met projecten zoals Thanos of Cortex. Deze oplossingen bieden globale query-mogelijkheden, deduplicatie, hoge beschikbaarheid en opslag in object storage.
Q. Kan ik Prometheus gebruiken om logs en traces te monitoren?
Prometheus is primair ontworpen voor het verzamelen van metrics. Voor logs kun je tools zoals Grafana Loki of de ELK Stack (Elasticsearch, Logstash, Kibana) gebruiken. Voor distributed tracing zijn oplossingen zoals Grafana Tempo of Jaeger meer geschikt. Deze tools kunnen vaak naast Prometheus en Grafana worden geïntegreerd voor een complete observability-stack.
Q. Wat zijn de meest voorkomende exporters die ik moet gebruiken?
Enkele van de meest gebruikte exporters zijn de Node Exporter (voor OS-metrics zoals CPU, geheugen, schijf), cAdvisor (voor container-metrics in Kubernetes), MySQL Exporter, Redis Exporter en Nginx Exporter. Er zijn honderden exporters beschikbaar voor diverse technologieën.
Q. Hoe voorkom ik ‘alert fatigue’ met Alertmanager?
Om alert fatigue te voorkomen, kun je Alertmanager configureren om alerts te groeperen op basis van labels (bijv. group_by), deduplicatie toe te passen, en inhibit_rules te gebruiken om minder belangrijke alerts te onderdrukken wanneer een kritieke alert actief is. Zorg er ook voor dat je alerts pas activeert na een bepaalde duur (FOR-clausule) om flapperende alerts te minimaliseren.
Bedankt voor het lezen!
Het implementeren van een robuuste monitoringstrategie met Prometheus en Grafana is een cruciale stap naar veerkrachtige en hoogwaardige cloud-native applicaties in 2026. Door de inzichten uit dit artikel toe te passen, kun je de prestaties en betrouwbaarheid van je systemen aanzienlijk verbeteren.
Vragen, opmerkingen of eigen ervaringen? Laat een reactie achter!